This assignment deals with optimizing memory intensive code.
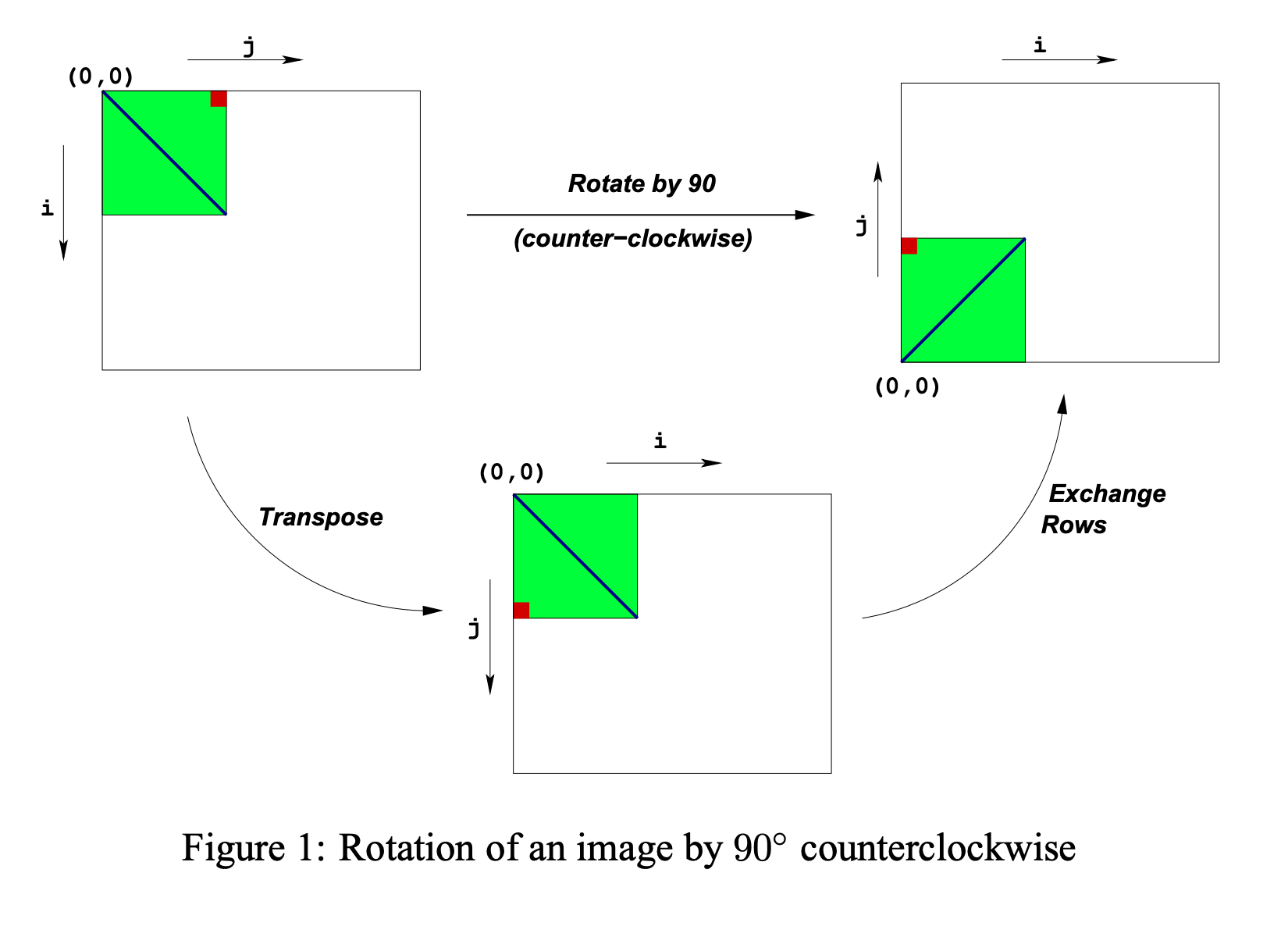
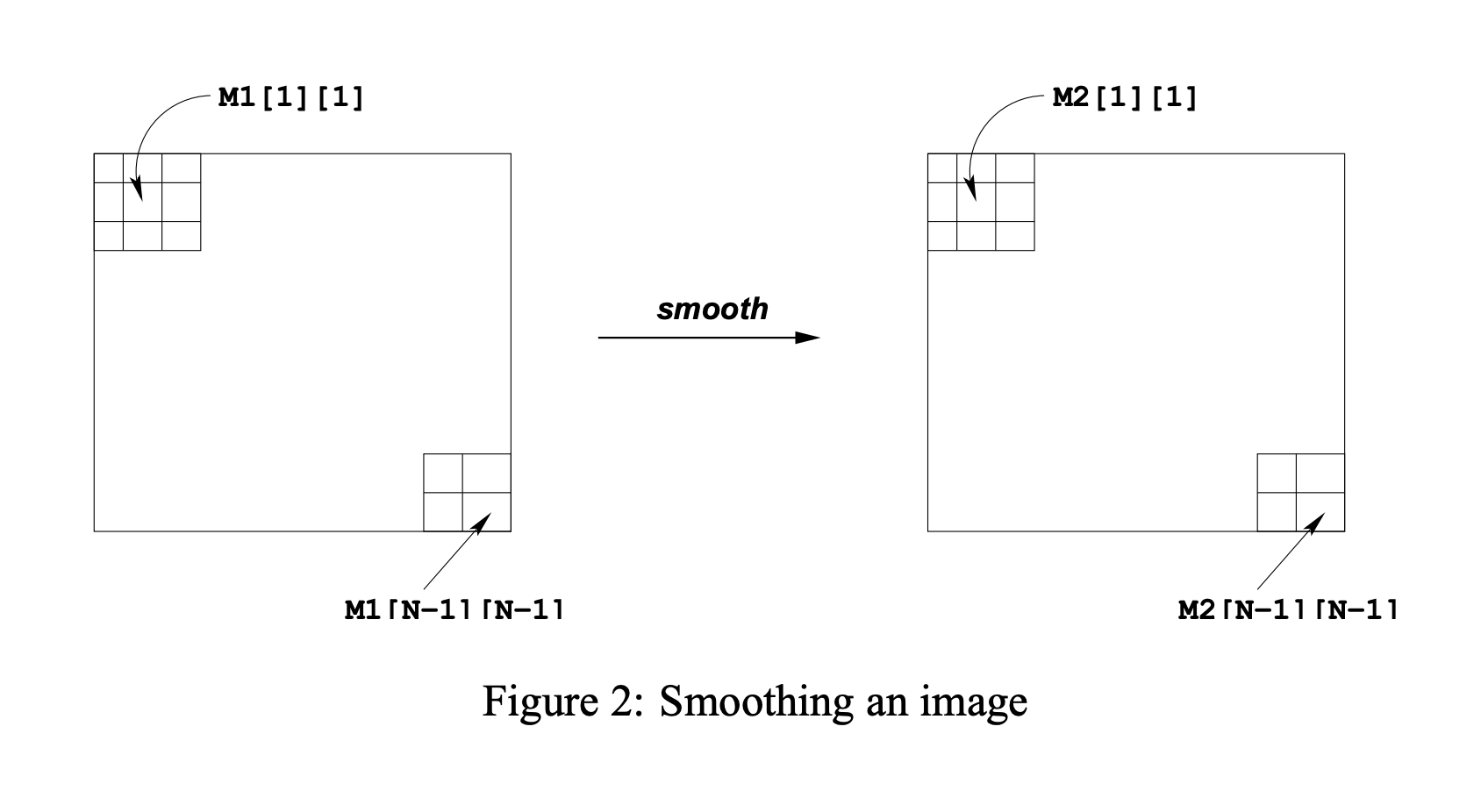
In this lab, we will consider two image processing operations: rotate, which rotates an image counter-clockwise by 90◦ , and smooth, which “smooths” or “blurs” an image.
The only file you will be modifying and handing in is kernels.c.
The driver.c program is a driver program that allows you to evaluate the performance of your solutions.
Use the command make driver to generate the driver code and run it with the command ./driver.
Performance measures
You will need to remake driver each time you change the code in kernels.c.
Overall performance is calculated by $$ R = \sqrt[5]{R_{64} \times R_{128} \times R_{256} \times R_{512} \times R_{1024} } $$
Versioning
You will be writing many versions of the rotate and smooth routines.
To help you compare the performance of all the different versions you’ve written, we provide a way of “registering” functions.
For example, the file kernels.c that we have provided you contains the following functions
/********************************************************* * config.h - Configuration data for the driver.c program. *********************************************************/ #ifndef _CONFIG_H_ #define _CONFIG_H_
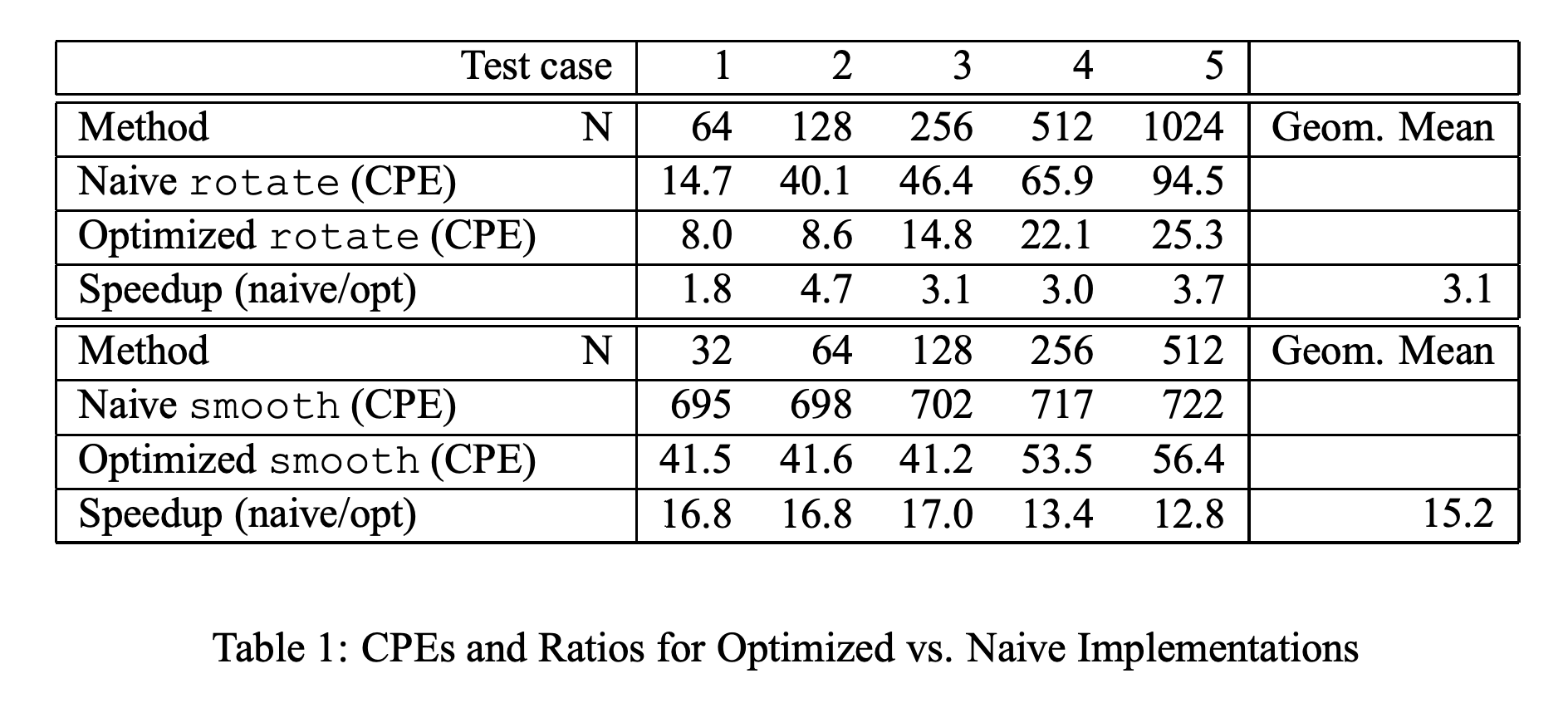
/* * CPEs for the baseline (naive) version of the rotate function that * was handed out to the students. Rd is the measured CPE for a dxd * image. Run the driver.c program on your system to get these * numbers. */ #define R64 14.7 #define R128 40.1 #define R256 46.4 #define R512 65.9 #define R1024 94.5
/* * CPEs for the baseline (naive) version of the smooth function that * was handed out to the students. Sd is the measure CPE for a dxd * image. Run the driver.c program on your system to get these * numbers. */ #define S32 695 #define S64 698 #define S128 702 #define S256 717 #define S512 722
/****************************************************** * Your different versions of the rotate kernel go here ******************************************************/
/* * naive_rotate - The naive baseline version of rotate */ char naive_rotate_descr[] = "naive_rotate: Naive baseline implementation"; voidnaive_rotate(int dim, pixel *src, pixel *dst) { int i, j; for (i = 0; i < dim; i++) for (j = 0; j < dim; j++){ dst[RIDX(dim-1-j, i, dim)] = src[RIDX(i, j, dim)]; } }
/* * rotate - Your current working version of rotate * IMPORTANT: This is the version you will be graded on */ char rotate_descr[] = "rotate: My implementation, Optimized"; voidrotate(int dim, pixel *src, pixel *dst) { int i ; int j ; int bound = dim - 7; //unrolling by 8, since we can assume the dim is k*32 and make use of cache //notice that unroll bound is N-step+1
int src_head ; int dst_head ;
for ( i = 0 ; i < dim ; i++){
//compute start address for src and dst src_head = RIDX(i, 0, dim); dst_head = RIDX(dim - 1 , i, dim);
for (j = 0 ; j < bound ; j+=8){
int decreasement = j * dim; int decreased_dst = dst_head - decreasement ; int increased_src = src_head + j;
//all 8 statements can be executed independently(simultaneously) since there is no data dependency between them dst[decreased_dst ] = src[increased_src]; dst[decreased_dst - dim] = src[increased_src + 1]; dst[decreased_dst - (dim << 1)] = src[increased_src + 2]; dst[decreased_dst - (dim << 1) - dim] = src[increased_src + 3]; dst[decreased_dst - (dim << 2)] = src[increased_src + 4]; dst[decreased_dst - (dim << 2) - dim] = src[increased_src + 5]; dst[decreased_dst - (dim << 2) - (dim << 1)] = src[increased_src + 6]; dst[decreased_dst - (dim << 3) + dim ] = src[increased_src + 7]; }
}
} char copy_descr [] = "copyed from https://github.com/Exely/CSAPP-Labs/blob/master/notes/perflab.md"; voidcopyrotate(int dim, pixel *src, pixel *dst) { int i, j, a, b; int sdim = dim - 1; for (i = 0; i < dim; i += 8) { for (j = 0; j < dim; j += 8) { for (a = i; a < i + 8; a++) { for (b = j; b < j + 8; b++) { dst[RIDX(sdim - b, a, dim)] = src[RIDX(a, b, dim)]; } } } } }
/********************************************************************* * register_rotate_functions - Register all of your different versions * of the rotate kernel with the driver by calling the * add_rotate_function() for each test function. When you run the * driver program, it will test and report the performance of each * registered test function. *********************************************************************/