Virtual Memory
virtual memory provides three important capabilities
- Uses main memory efficiently by treating it as a cache for an address space stored on disk, keeping only the active areas in main memory and transferring data back and forth between disk and memory as needed
- It simplifies memory management by providing each process with a uniform address space.
- It protects the address space of each process from corruption by other processes.(Each process has its own page table)
A major reason for its success is that it works silently and automatically, without any intervention from the application programmer
9.1 Physical and Virtual Addressing
Physical : The main memory of a computer system is organized as an array of M contiguous byte-size cells. Each byte has a unique physical address . The first byte has an address of 0
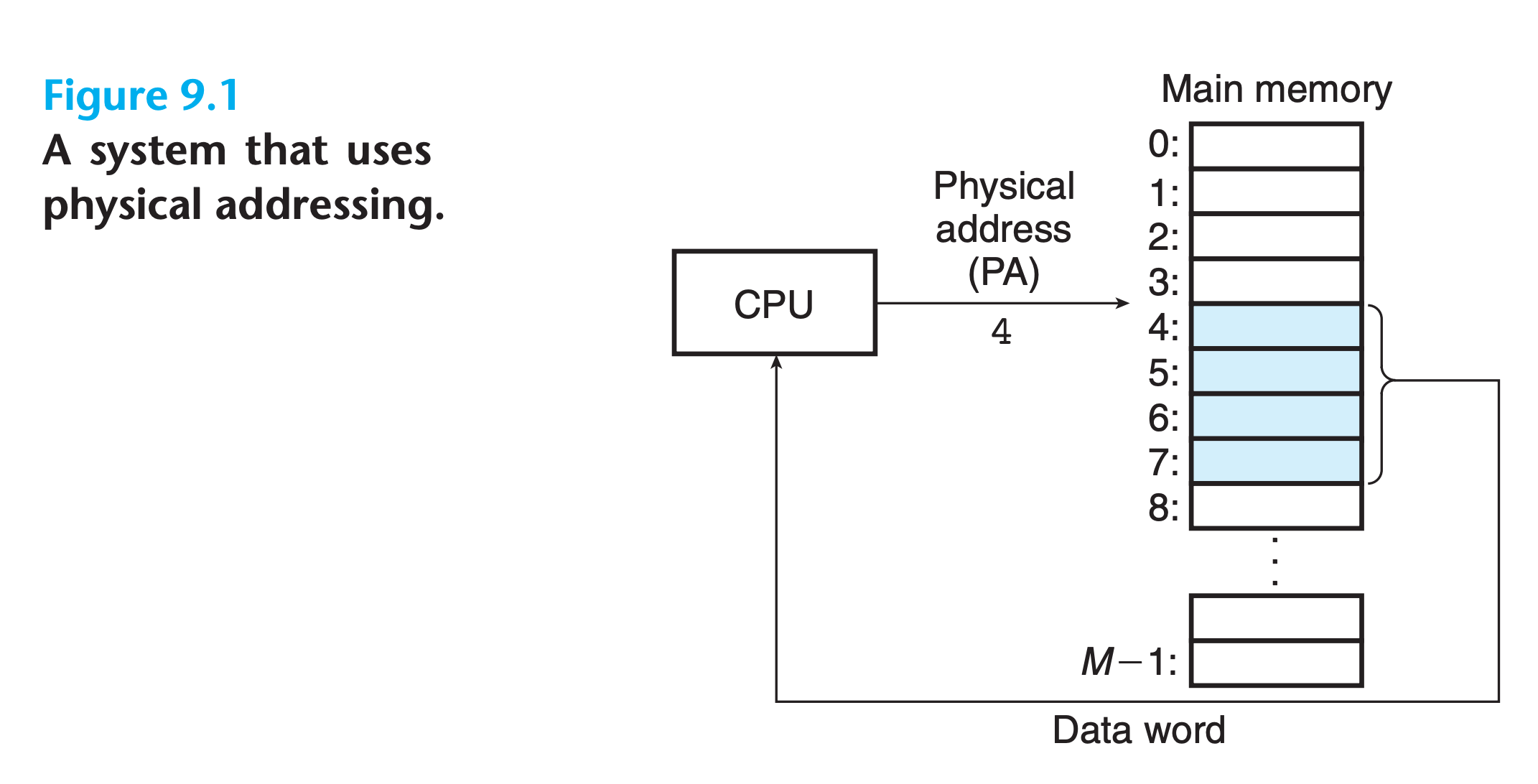
Virtual : the CPU accesses main memory by generating a virtual address, which is converted to the appropriate physical address before being sent to main memory. The task of converting a virtual address to a physical one is known as address translation
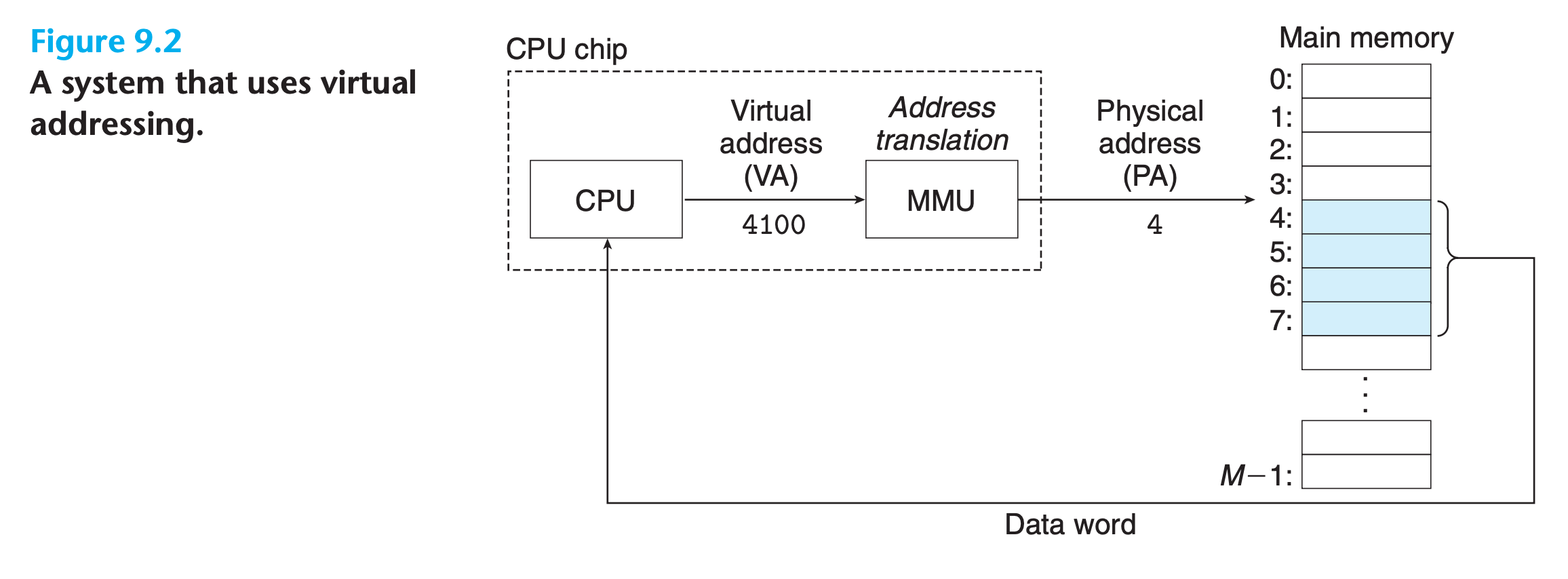
9.2 Address Spaces
An address space is an ordered set of nonnegative integer addresses {0, 1, 2,…}
If the integers in the address space are consecutive, then we say that it is a linear address space.
Virtual Memory Space
$$
{ 0,1,2,…,N-1} , N=2^n
$$
- n is the number of bits can be used to represent addresses(width of address bus)
- In modern system, n is either 32 or 64
Phiscal Memory Space
$$
{0,1,2,…,M-1}
$$
- M doesn’t need to be power of 2
- M is the number of bytes we acutally have in memory
Basic Concept of Virtual Memory
Allow each data object to have multiple independent addresses, each chosen from a different address space.
(Each byte of main memory has a virtual address chosen from the virtual address space, and a physical address chosen from the physical address space.)
9.3 VM as a Tool for Caching
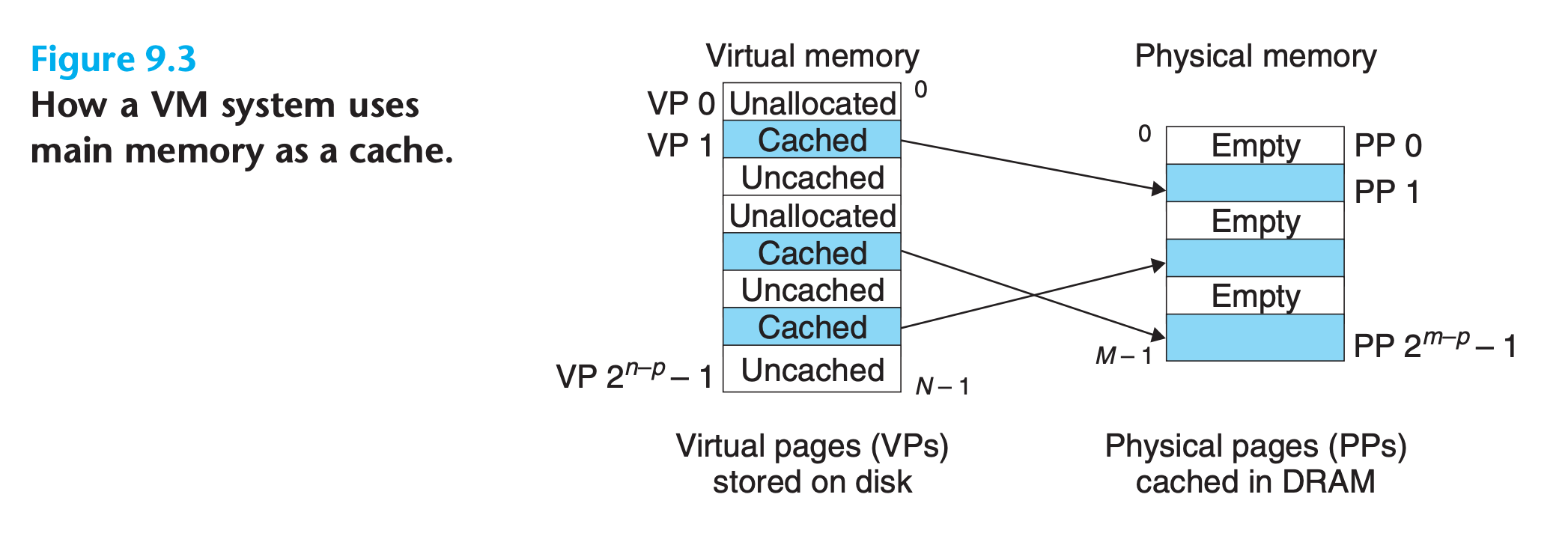
Conceptually, a virtual memory is organized as an array of N contiguous byte-size cells stored on disk
- The contents of the array on disk are cached in main memory
- The system partitioning the virtual memory into fixed-size blocks called virtual pages, P bytes per page
- Physical memory is partitioned into physical pages , also P bytes in size
At any point in time, the set of virtual pages is partitioned into three disjoint subsets:
- Unallocated.
- Pages that have not yet been allocated (or created) by the VM system.
- Unallocated blocks do not have any data associated with them, and thus do not occupy any space on disk.
- Cached
- Allocated pages that are currently cached in physical memory
- Uncached.
- Allocated pages that are not cached in physical memory
9.3.1 DRAM Cache Organization
the organization of the DRAM cache is driven entirely by the enormous cost of misses
- Because of the large miss penalty and the expense of accessing the first byte, virtual pages tend to be large—typically 4 KB to 2 MB
- Due to the large miss penalty, DRAM caches are fully associative
- Only one set, any virtual page can be placed in any physical page
- Operating systems use much more sophisticated replacement algorithms for DRAM caches than the hardware does for SRAM caches.
- Because of the large access time of disk, DRAM caches always use write-back instead of write-through.
9.3.2 Page Tables
The address translation hardware reads the page table each time it converts a virtual address to a physical address.
The operating system is responsible for maintaining the contents of the page table and transferring pages back and forth between disk and DRAM.

- A page table is an array of page table entries (PTEs)
- Each page in the virtual address space has a PTE at a fixed offset in the page table.
- If the valid bit is set, the address field indicates the start of the corresponding physical page in DRAM where the virtual page is cached
Practice Problem 9.2
Determine the number of page table entries (PTEs) that are needed for the following combinations of virtual address size (n) and page size (P):
n $P=2^p$ Number of PTEs 12 1K 16 16K 24 2M 36 1G
My solution : :white_check_mark:
$$
2^n / P = 2^{n-p}
$$
| n | $P=2^p$ | Number of PTEs |
|---|---|---|
| 12 | 1K | 4 |
| 16 | 16K | 4 |
| 24 | 2M | 8 |
| 36 | 1G | 64 |
9.3.3 Page Hits
9.3.4 Page Faults
A DRAM cache miss is known as a page fault.
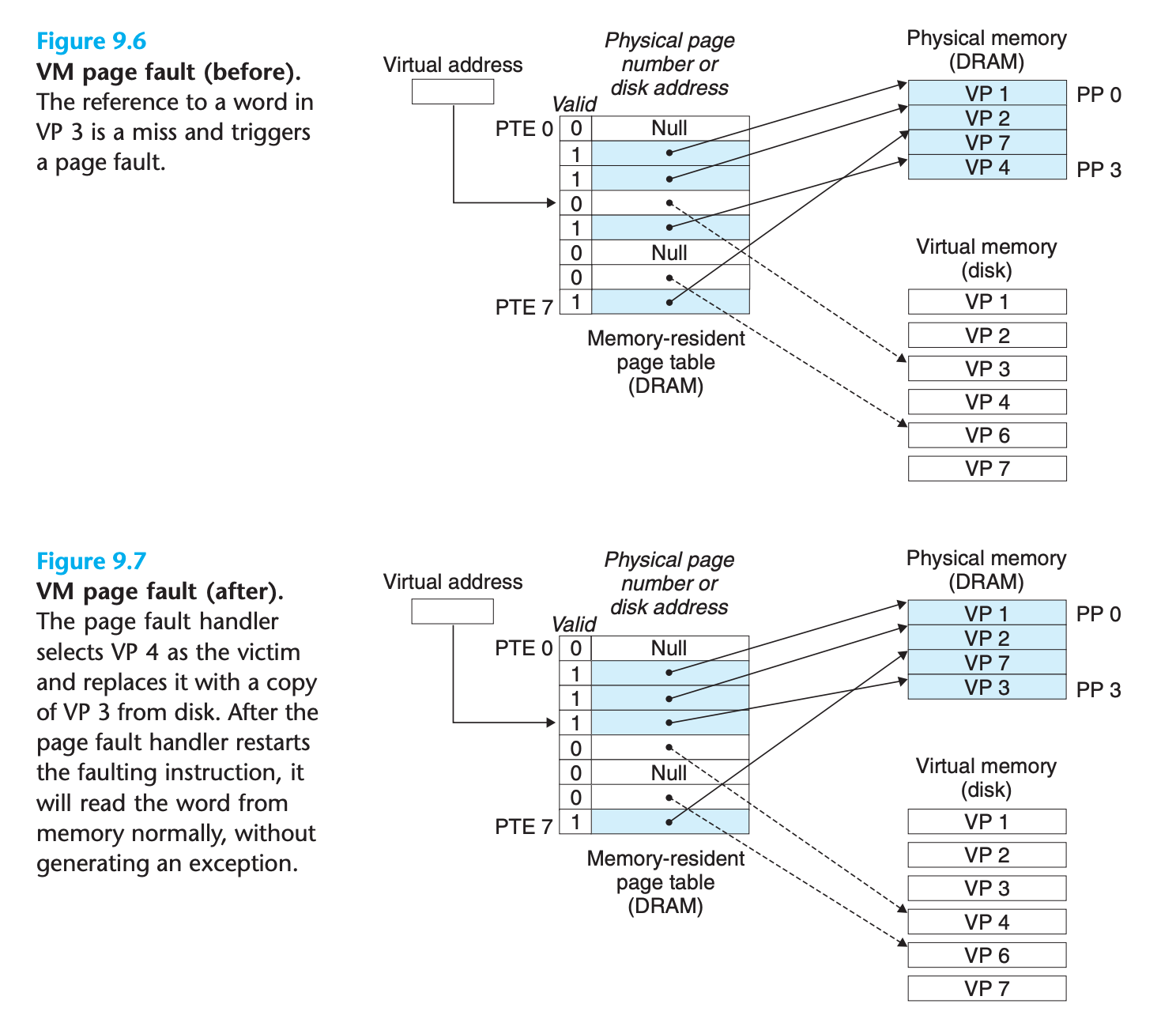
9.3.5 Allocating Pages
Figure 9.8 shows the effect on our example page table when the operating system allocates a new page of virtual memory—for example, as a result of calling malloc.
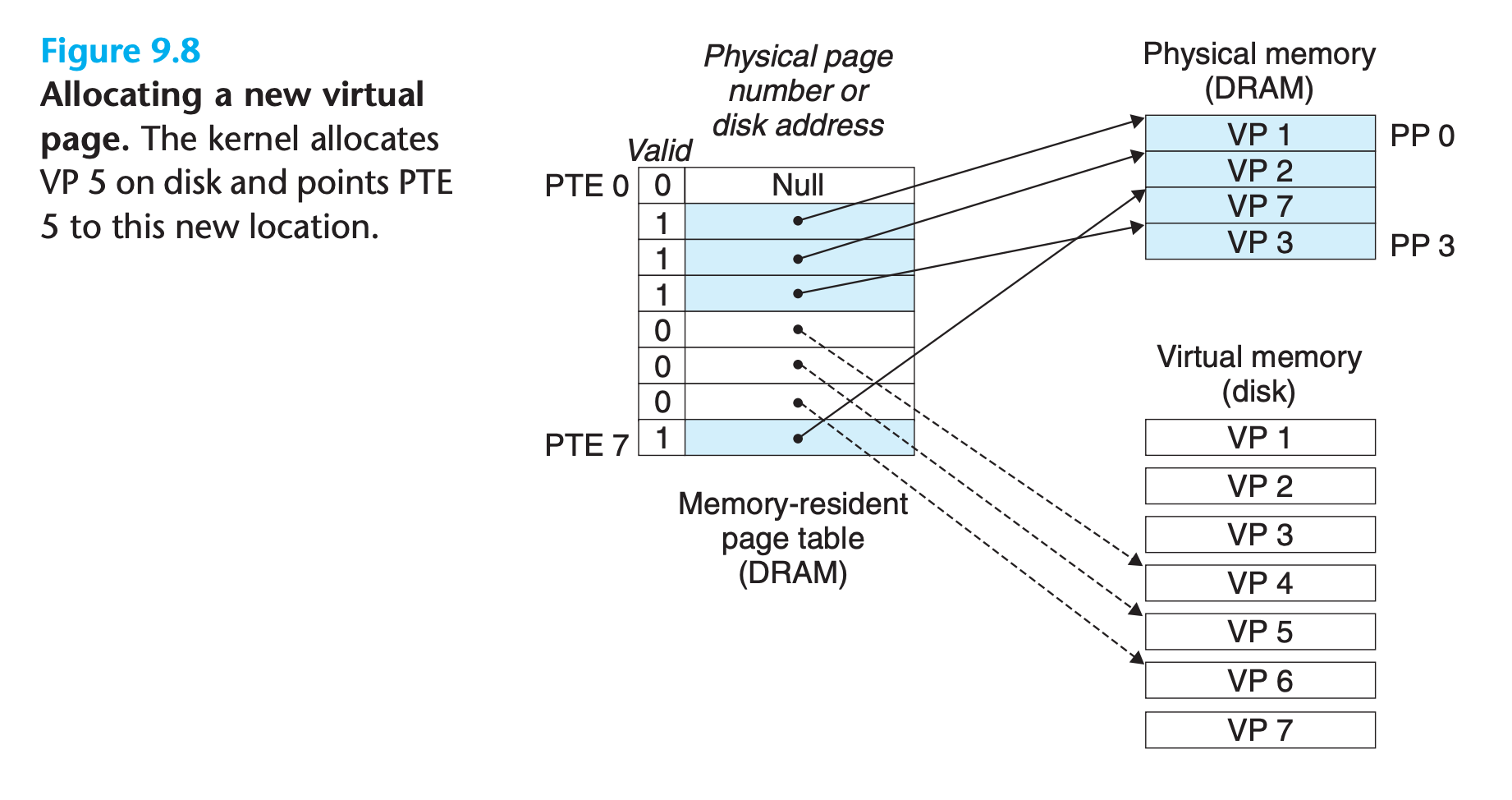
9.3.6 Locality to the Rescue Again
In practice, virtual memory works well, mainly because of locality.
Counting page faults
You can monitor the number of page faults (and lots of other information) with the Linux
getrusagefunction
9.4 VM as a Tool for Memory Management
In fact, operating systems provide a separate page table, and thus a separate virtual address space, for each process.
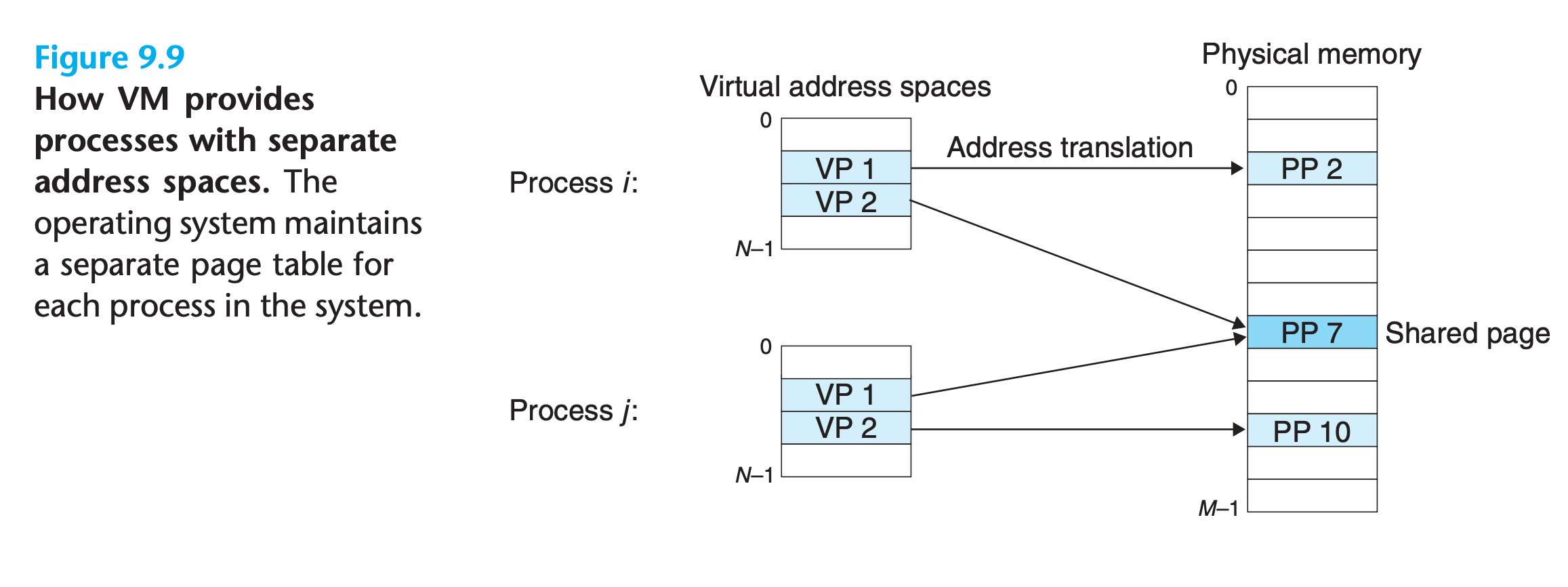
In particular, VM simplifies linking and loading, the sharing of code and data, and allocating memory to application
Simplifying linking
- A separate address space allows each process to use the same basic format for its memory image, regardless of where the code and data actually reside in physical memory
Simplifying loading.
- To load the .text and .data sections of an object file into a newly created process, the Linux loader allocates virtual pages for the code and data segments, marks them as invalid (i.e., not cached), and points their page table entries to the appropriate locations in the object file.
- the loader never actually copies any data from disk into memory
- The data are paged in automatically and on demand by the virtual memory system the first time each page is referenced(Copying is done by the OS)
Simplifying sharing
- For unique resources like user-stack, program code, the operating system creates page tables that map the corresponding virtual pages to disjoint physical pages.
- For shared resources like shared libraries, the operating system can arrange for multiple processes to share a single copy of this code by mapping the appropriate virtual pages in different processes to the same physical page
Simplifying memory allocation
- Because of the way page tables work, there is no need for the operating system to locate several contiguous pages of physical memory. The pages can be scattered randomly in physical memory.
9.5 VM as a Tool for Memory Protection
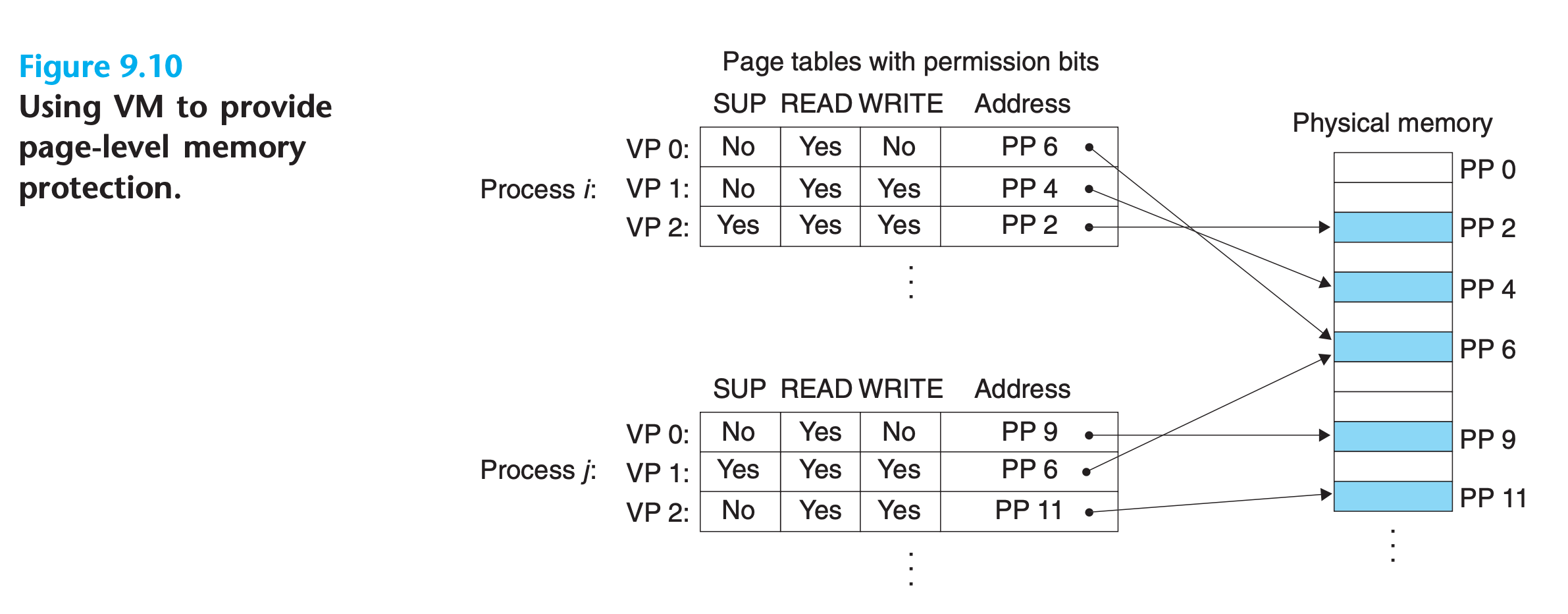
Providing separate virtual address spaces makes it easy to isolate the private memories of different processes. But the address translation mechanism can be extended in a natural way to provide even finer access control.
Since the address translation hardware reads a PTE each time the CPU generates an address, it is straightforward to control access to the contents of a virtual page by adding some additional permission bits to the PTE.
9.6 Address Translation
This section is going to explain how hardware work in address translation, but ignoring some details like timing

Formally, address translation is a mapping between the elements of an N element virtual address space (VAS) and an M element physical address space (PAS)
$$
MAP:VAS\rightarrow PAS \cup \O
$$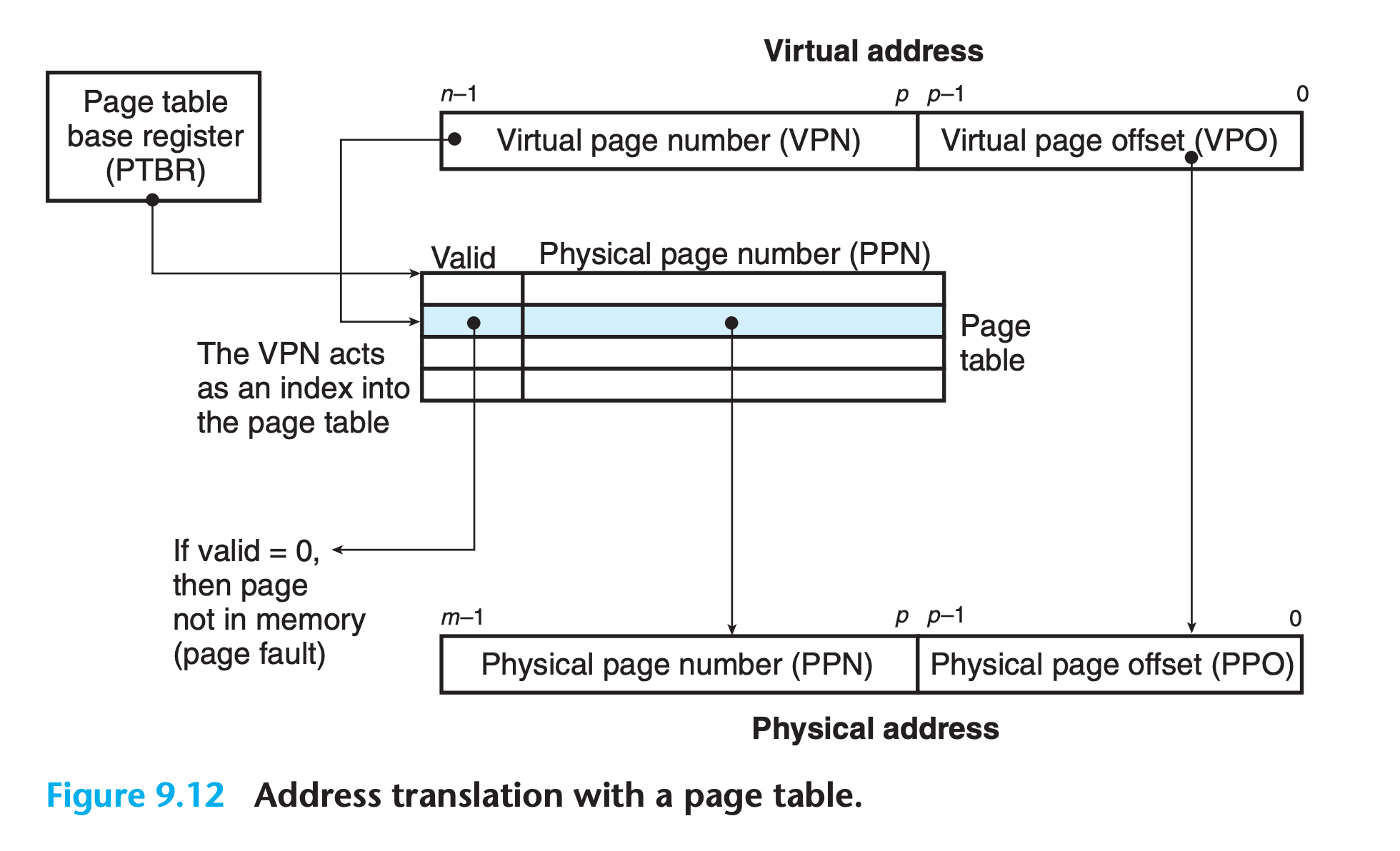
- A control register in the CPU, the page table base register (PTBR) points to the current page table.
- The n-bit virtual address has two components:
- $p$ bits virtual page offset (VPO)
- $(n − p)$ bits virtual page number (VPN).
- The MMU uses the VPN to select the appropriate PTE. For example, VPN 0 selects PTE 0, VPN 1 selects PTE 1, and so on
- The corresponding physical address is the concatenation of the physical page number (PPN)from the page table entry and the VPO from the virtual address.
- Notice that since the physical and virtual pages are both P bytes, the physical page offset (PPO)is identical to the VPO.
Page hit and Page fault
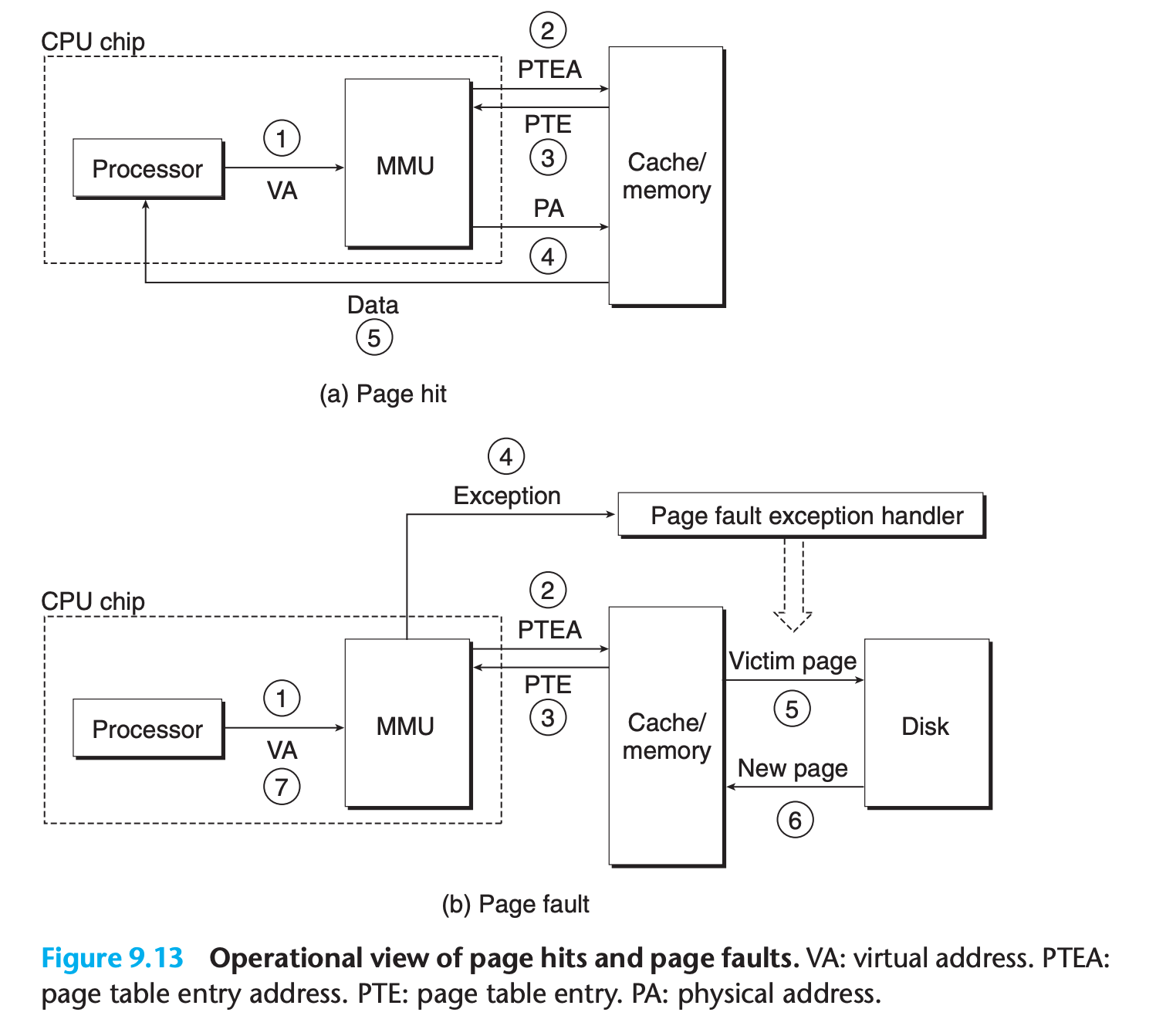
Page hit
- The processor generates a virtual address and sends it to the MMU.
- The MMU generates the PTE address and requests it from the cache/ main memory.
- The cache/main memory returns the PTE to the MMU.
- The MMU constructs the physical address and sends it to the cache/main memory.
- The cache/main memory returns the requested data word to the processor.
Page fault
The same as steps 1 to 3 in page hit
- The valid bit in the PTE is zero, so the MMU triggers an exception, which transfers control in the CPU to a page fault exception handler in the operating system kernel.
- The fault handler identifies a victim page in physical memory, and if that page has been modified, pages it out to disk.
- The fault handler pages in the new page and updates the PTE in memory
- The fault handler returns to the original process, causing the faulting instruction to be restarted. The CPU resends the offending virtual address to the MMU. Because the virtual page is now cached in physical memory, there is a hit, and after the MMU performs the steps in Figure 9.13(a), the main memory returns the requested word to the processor.
Practice Problem 9.3
Given a 64-bit virtual address space and a 32-bit physical address, determine the number of bits in the VPN, VPO, PPN, and PPO for the following page sizes P:
P (number of)VPN bits VPO bits PPN bits PPO bits 1kb 2kb 4kb 16kb
My solution : :white_check_mark:
$$
2^{64} \div 2^{10} = 2^{54} (\text{pages})
$$
$$
VPN=54(bits)
$$
| P | (number of)VPN bits | VPO bits | PPN bits | PPO bits |
|---|---|---|---|---|
| 1kb | 54 | 10 | 22 | 10 |
| 2kb | 53 | 11 | 21 | 11 |
| 4kb | 52 | 12 | 20 | 12 |
| 16kb | 50 | 14 | 18 | 14 |
9.6.1 Integrating Caches and VM
In any system that uses both virtual memory and SRAM caches, there is the issue of whether to use virtual or physical addresses to access the SRAM cache.
Most systems opt for physical addressing
- It is straightforward for multiple processes to have blocks in the cache at the same time and to share blocks from the same virtual pages
- The cache does not have to deal with protection issues, because access rights are checked as part of the address translation process.
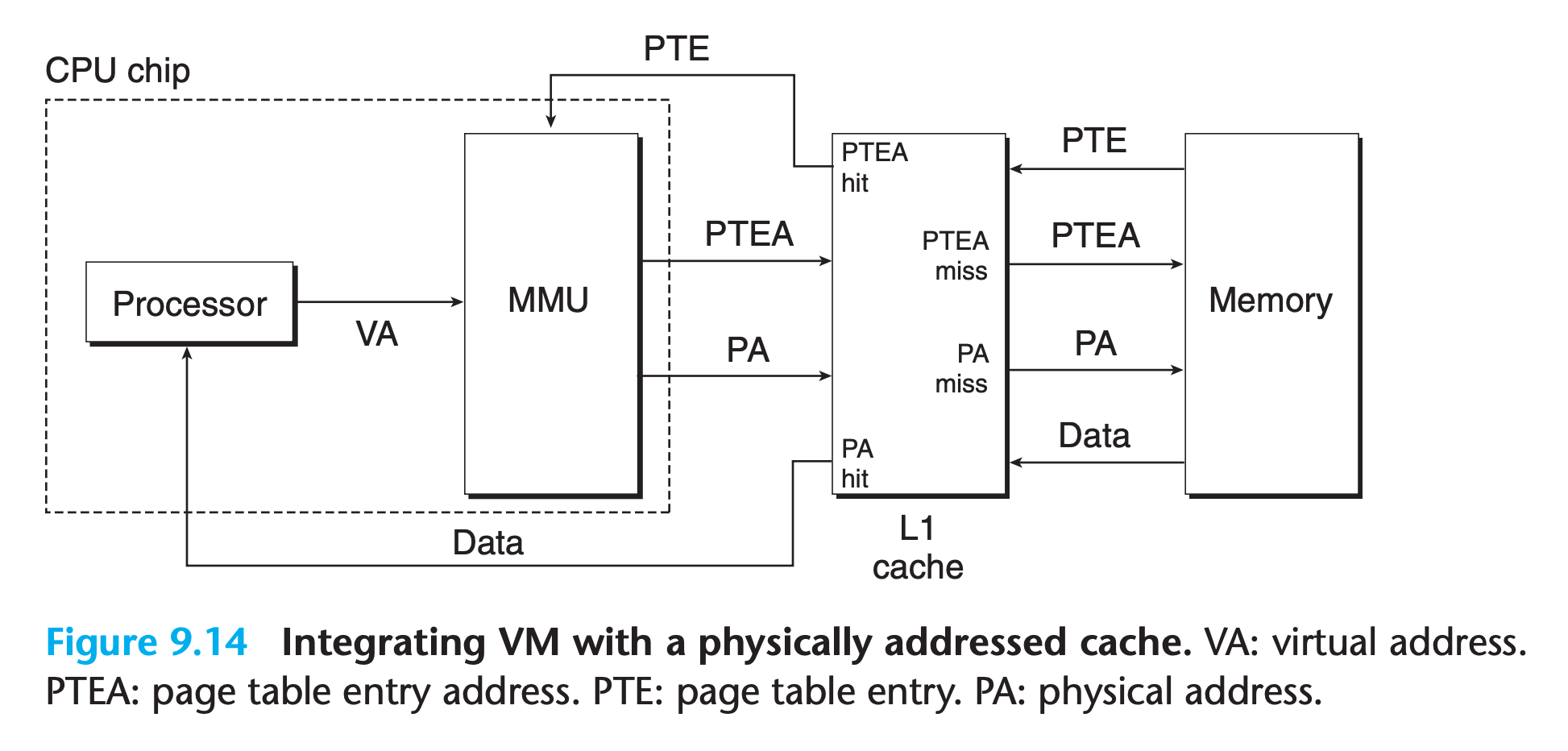
9.6.2 Speeding Up Address Translation with a TLB
Many systems try to eliminate even the cost of finding PTE in level-1 cache by including a small cache of PTEs in the MMU called a translation lookaside buffer (TLB).
- A TLB is a small, virtually addressed cache where each line holds a block consisting of a single PTE.
- A TLB usually has a high degree of associativity

TLB Operation
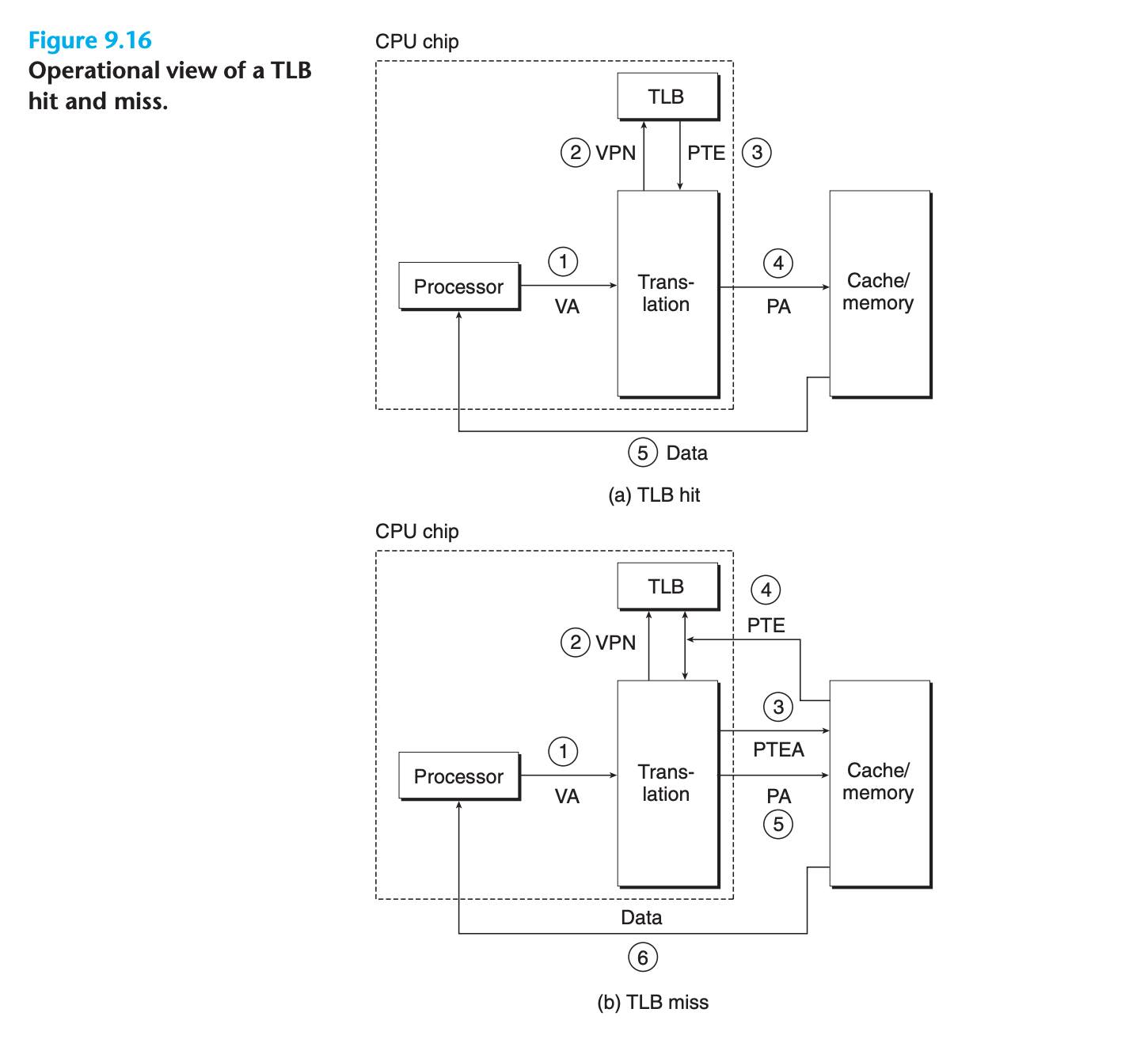
9.6.3 Multi-Level Page Tables
If we only use a single page table to do the translation, we will have a very large page table resident in memory
The common approach for compacting the page table is to use a hierarchy of page tables instead
1 | //Just like two star pointer, it is a page table to page table |
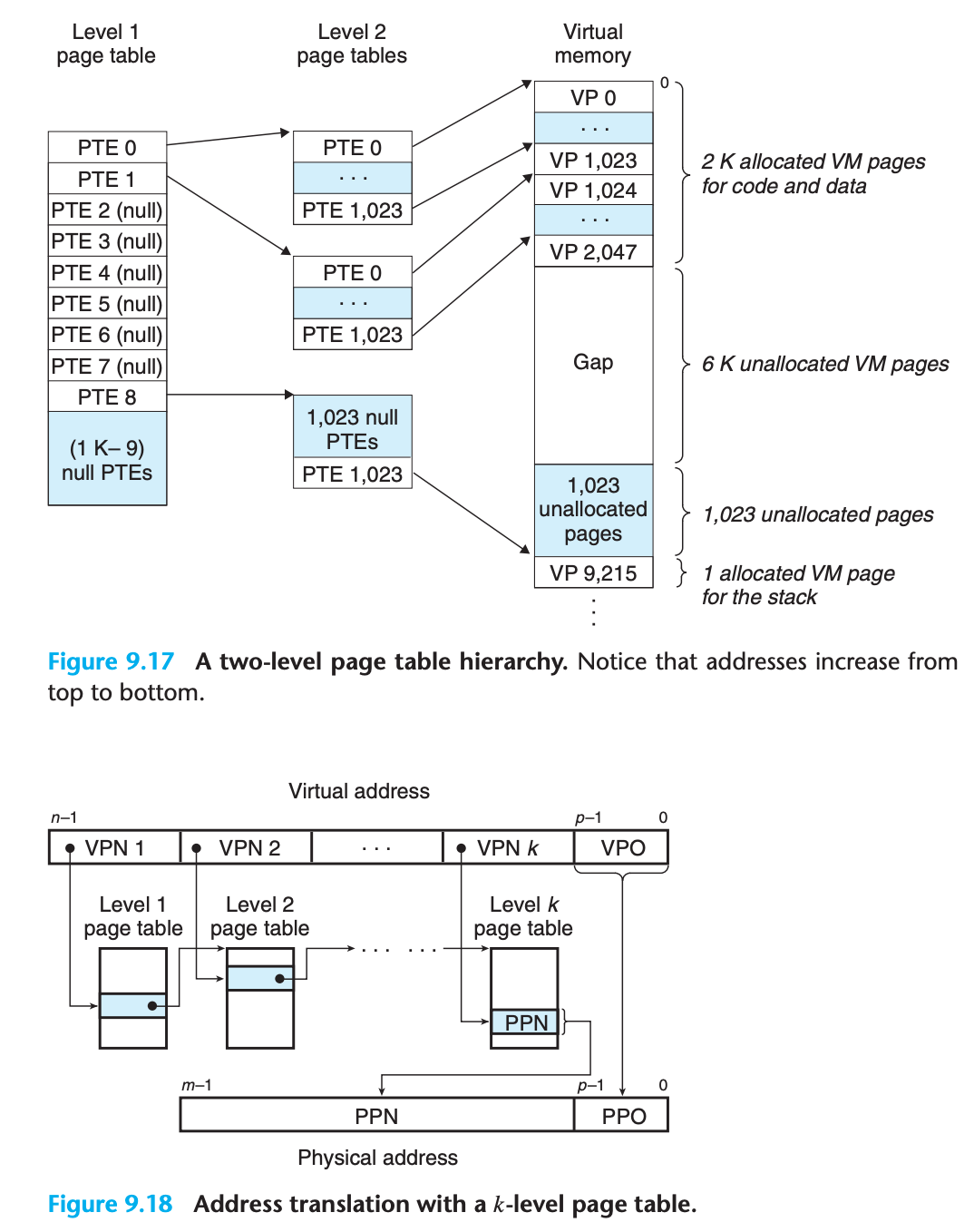
Why multiple level tables save space ?
- level 2(or lower levels) are generated dynamically, they only exist when they are needed).
sizeof(PageTable*) < sizeof(PageTable)
9.6.4 Putting It Together: End-to-End Address Translation
9.7 Case Study: The Intel Core i7/Linux Memory System
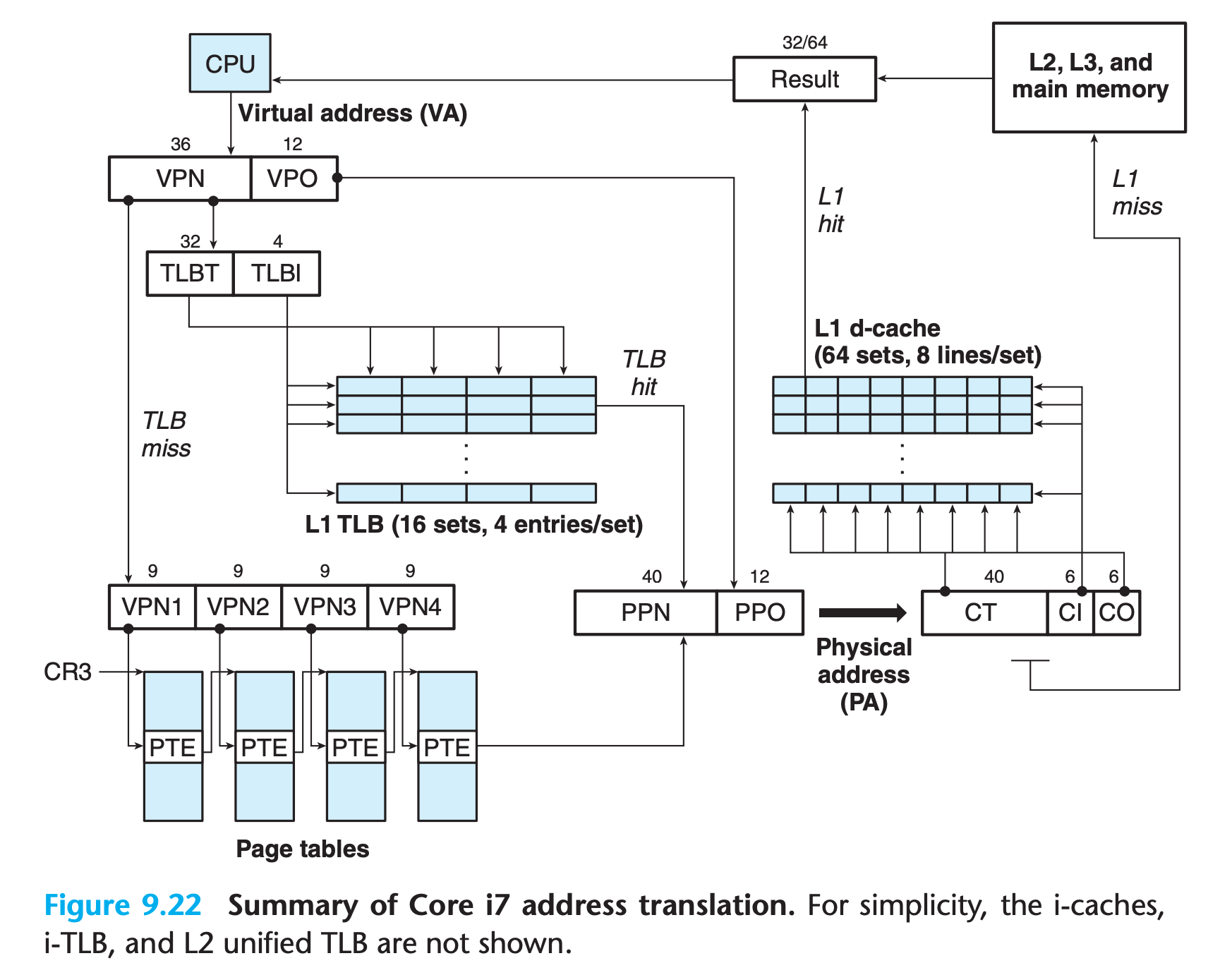
9.7.1 Core i7 Address Translation

9.7.2 Linux Virtual Memory System
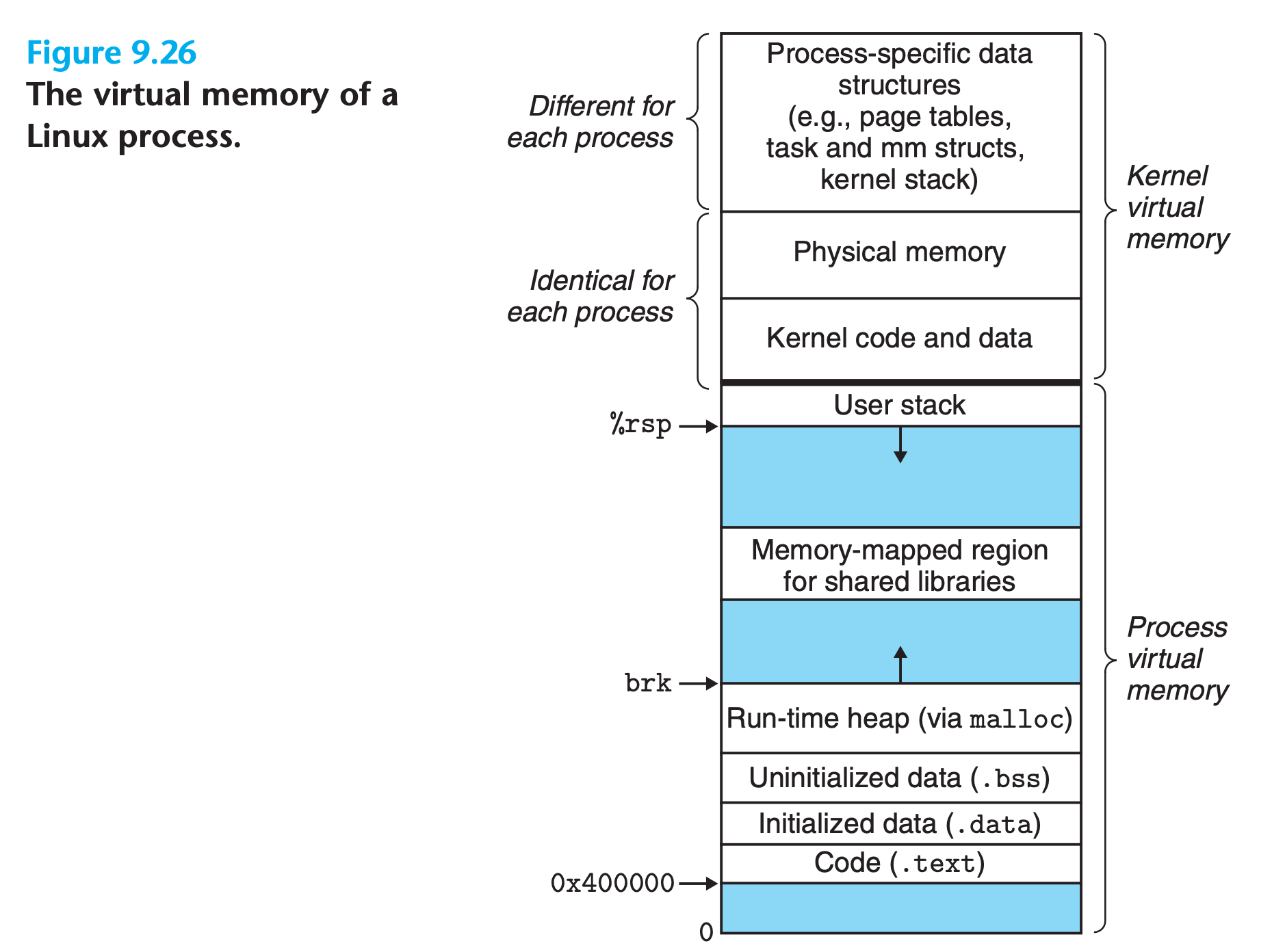
Each process shares the kernel’s code and global data structures.
Linux Virtual Memory Areas
Linux organizes the virtual memory as a collection of areas (also called segments).
- An area is a contiguous chunk of existing (allocated) virtual memory whose pages are related in some way
- the code segment, data segment, heap, shared library segment, and user stack are all distinct areas.
- The kernel maintains a distinct task structure (
task_ structin the source code) for each process in the system.- The elements of the task structure either contain or point to all of the information that the kernel needs to run the process (e.g., the PID, pointer to the user stack, name of the executable object file, and program counter)
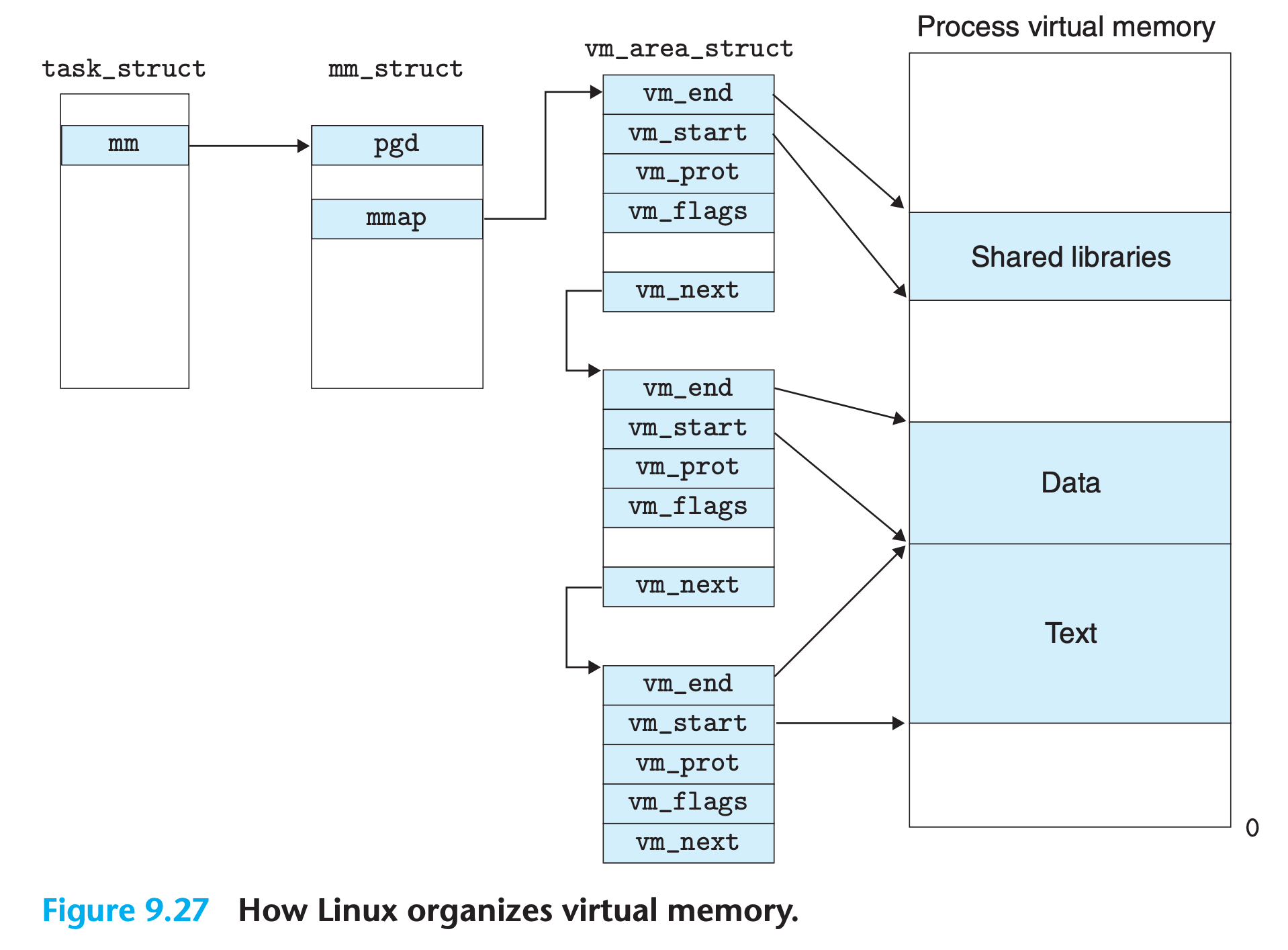
- One of the entries in the task structure points to an
mm_structthat characterizes the current state of the virtual memory.pgd, which points to the base of the level 1 table (the page global directory)mmap, which points to a list ofvm_area_structs(area structs), each of which characterizes an area of the current virtual address space
fvm_start Points to the beginning of the area.
vm_end. Points to the end of the area.
vm_prot. Describes the read/write permissions for all of the pages contained in the area.
vm_flags. Describes (among other things) whether the pages in the area are shared with other processes or private to this process.
vm_next. Points to the next area struct in the list.
Linux Page Fault Exception Handling
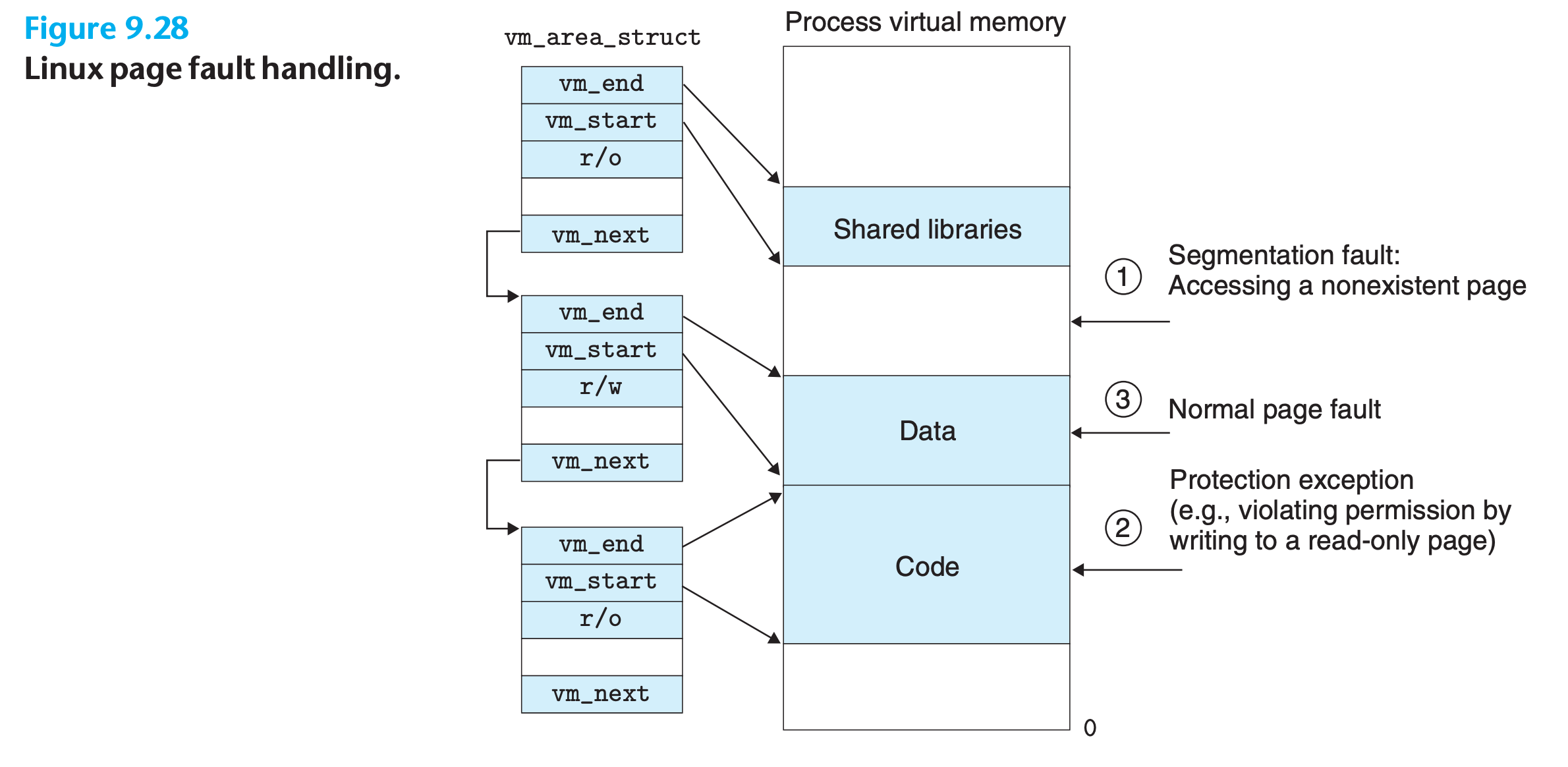
1 | def isValid(trigger_address): |
9.8 Memory Mapping
Linux initializes the contents of a virtual memory area by associating it with an object on disk, a process known as memory mapping
Areas can be mapped to one of two types of objects:
- Regular file in the Linux file system
- The file section is divided into page-size pieces, with each piece containing the initial contents of a virtual page.
- Because of demand paging, none of these virtual pages is actually swapped into physical memory until the CPU first touches the page
- If the area is larger than the file section, then the area is padded with zeros.
- Anonymous file
- An area can also be mapped to an anonymous file, created by the kernel, that contains all binary zeros.
- The first time the CPU touches a virtual page in such an area, the kernel finds an appropriate victim page in physical memory, swaps out the victim page if it is dirty, overwrites the victim page with binary zeros, and updates the page table to mark the page as resident.
- Notice that no data are actually transferred between disk and memory if no dirty page
In either case, once a virtual page is initialized, it is swapped back and forth between a special swap file(aka swap space or the swap area) maintained by the kernel.
At any point in time, the swap space bounds the total amount of virtual pages that can be allocated by the currently running processes.
9.8.1 Shared Objects Revisited
If the virtual memory system could be integrated into the conventional file system, then it could provide a simple and efficient way to load programs and data into memory
An object can be mapped into an area of virtual memory as either a shared object or a private object
Shared
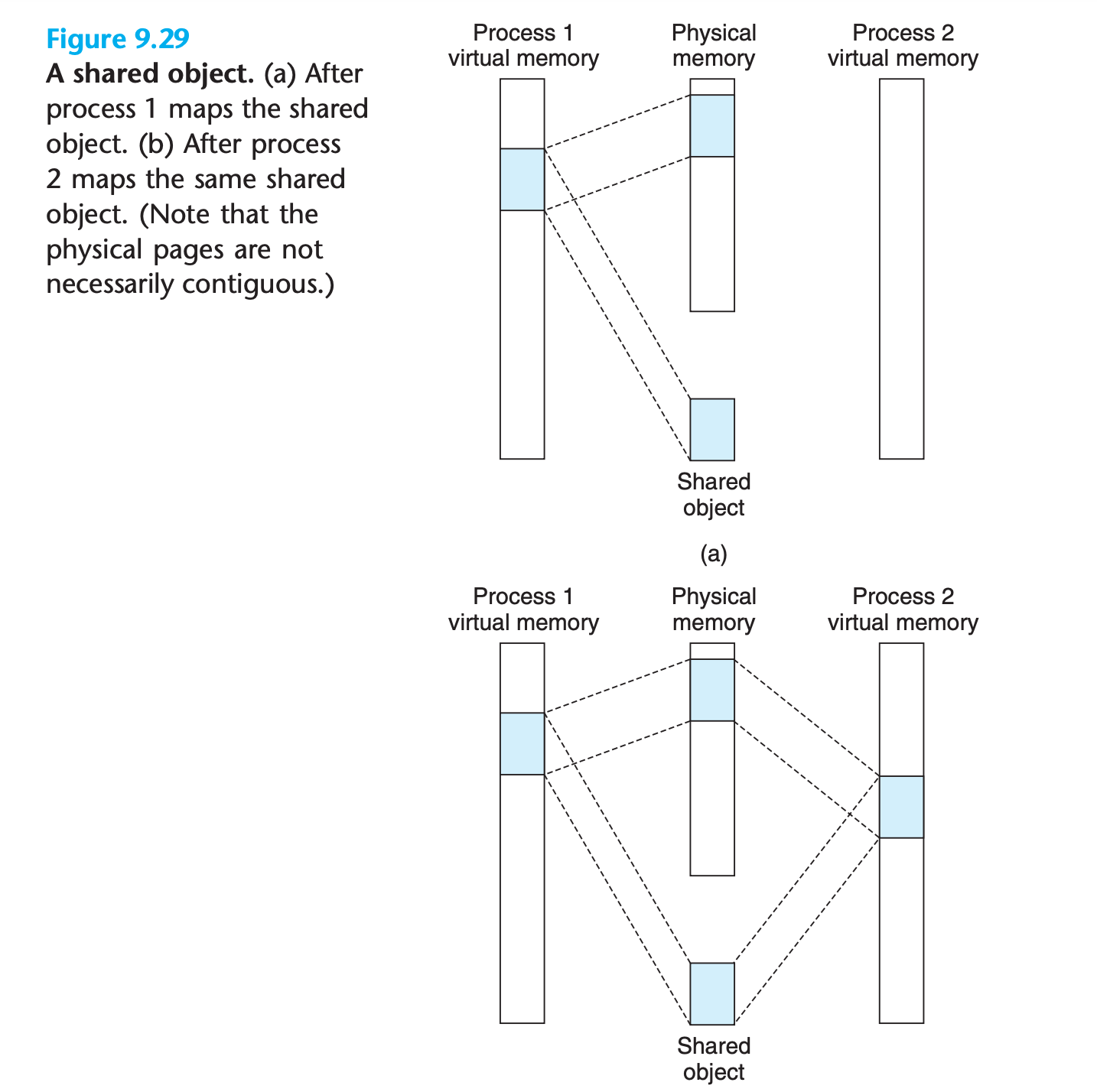
- Only a single copy of the shared object needs to be stored in physical memory, even though the object is mapped into multiple shared areas.
Private
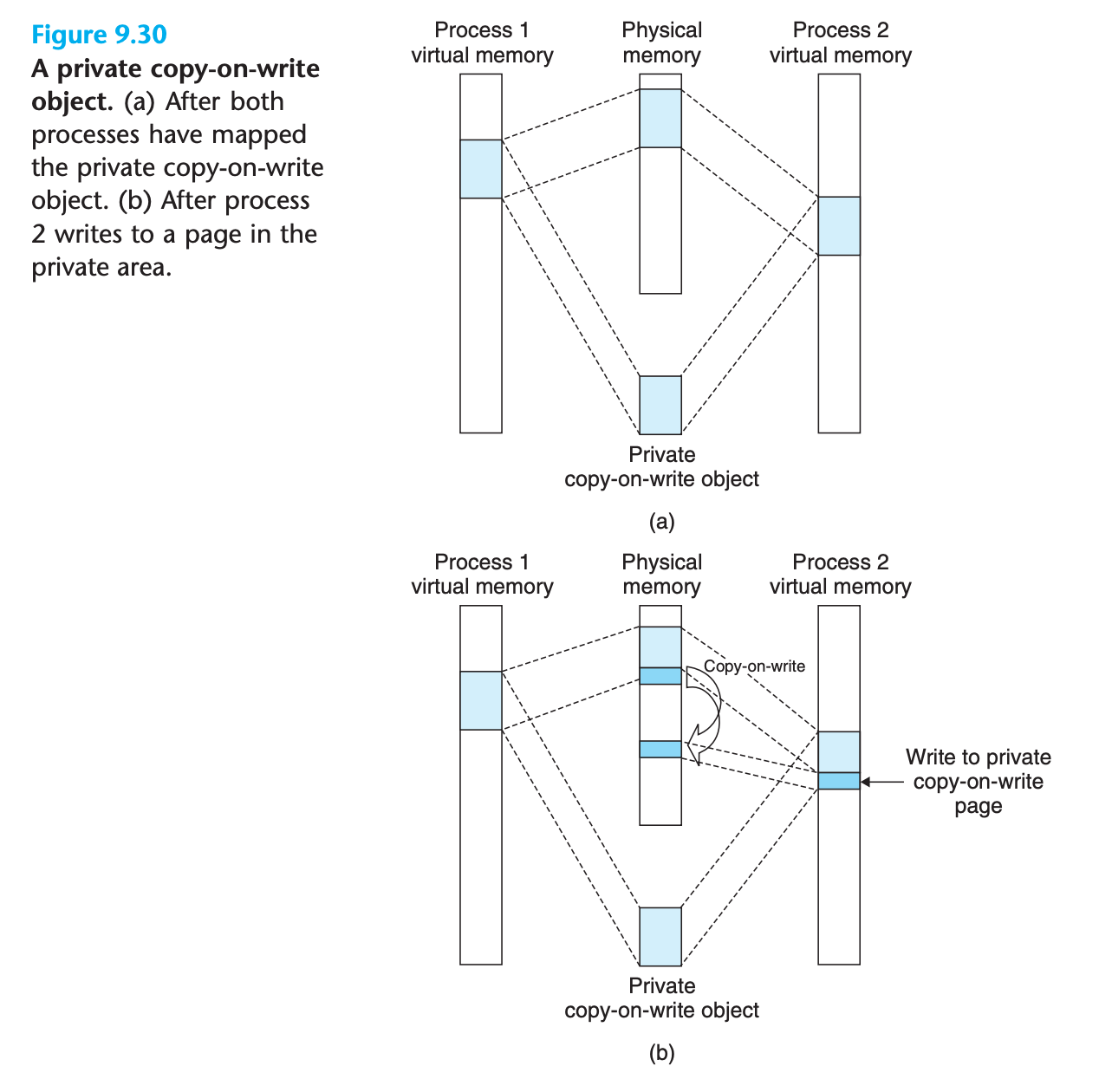
- Private objects are mapped into virtual memory using a clever technique known as copy-on-write
- A private object begins life in exactly the same way as a shared object, with only one copy of the private object stored in physical memory
- For each process that maps the private object, the page table entries for the corresponding private area are flagged as read-only, and the area struct is flagged as private copy-on-write.
- As soon as a process attempts to write to some page in the private area, the write triggers a protection fault.
- When the fault handler notices that the protection exception was caused by the process trying to write to a page in a private copy-on-write area, it creates a new copy of the page in physical memory, updates the page table entry to point to the new copy, and then restores write permissions to the page
- When the fault handler returns, the CPU re-executes the write, which now proceeds normally on the newly created page.
- By deferring the copying of the pages in private objects until the last possible moment, copy-on-write makes the most efficient use of scarce physical memory
9.8.2 The fork Function Revisited
When the fork function is called by the current process :
- The kernel creates various data structures for the new process and assigns it a unique PID.
- creates exact copies of the current process’s
mm_struct,area structs, andpage tables.(Now the memory copy of the old process has already been created!!!) - It flags each page in both processes as read-only, and flags each area struct in both processes as private copy-on-write.
- When the
forkreturns in the new process, the new process now has an exact copy of the virtual memory as it existed when theforkwas called - When either of the processes performs any subsequent writes, the copy-on-write mechanism creates new pages
9.8.3 The execve Function Revisited
When execve("a.out", NULL, NULL);, the following steps are performed
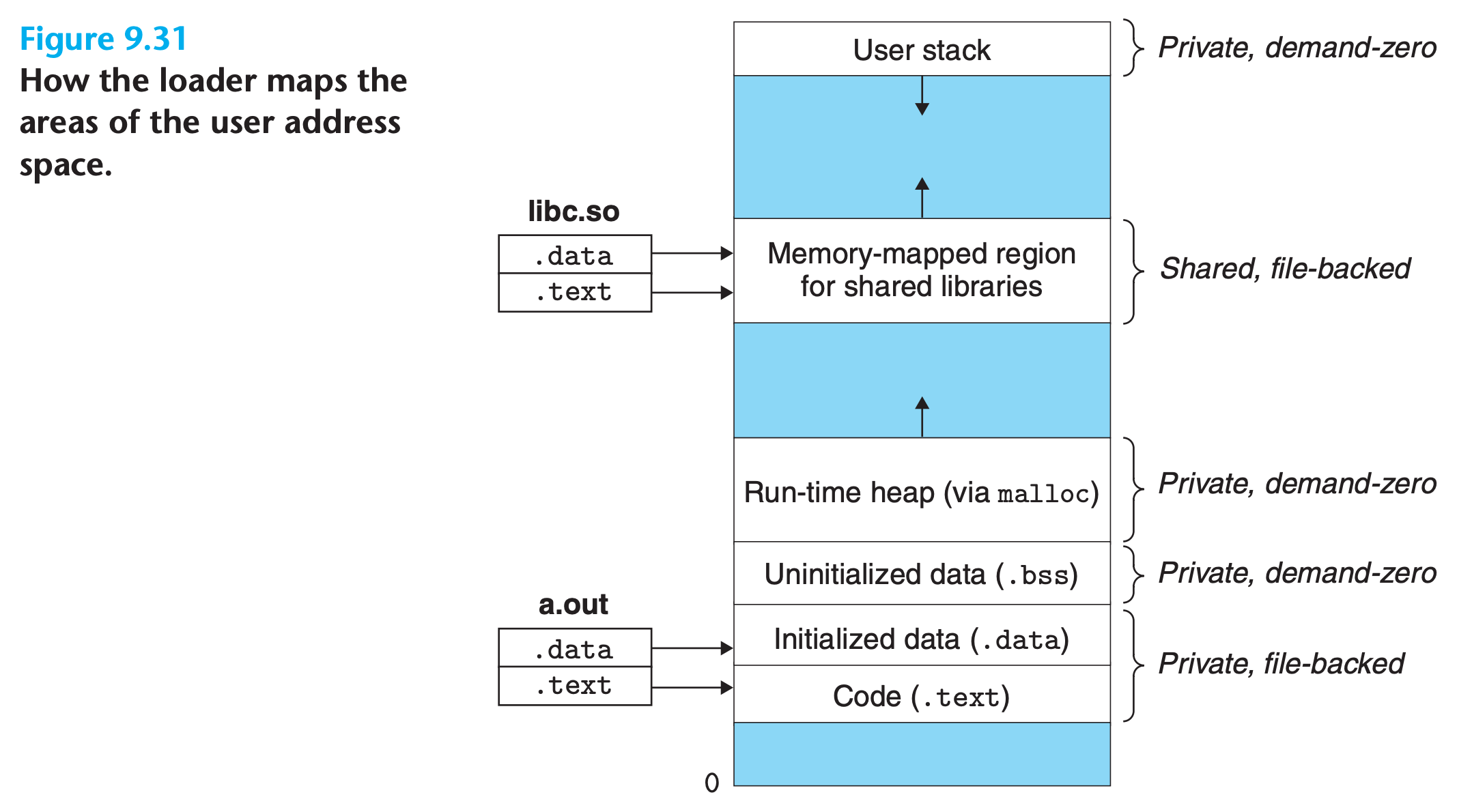
- Delete existing user areas. Delete the existing area structs in the user portion of the current process’s virtual address
- Map private areas. Create new area structs for the code, data, bss, and stack areas of the new program. All of these new areas are private copy-on-write. The code and data areas are mapped to the .text and .data sections of the a.out file. The bss area is demand-zero, mapped to an anonymous file whose size is contained in a.out. The stack and heap area are also demand-zero, initially of zero length.
- Map shared areas.
- Set the program counter (PC). The last thing that execve does is to set the program counter in the current process’s context to point to the entry point in the code area.
9.8.4 User-Level Memory Mapping with the mmap Function
Linux processes can use the mmap function to create new areas of virtual memory and to map objects into these areas.
1 |
|
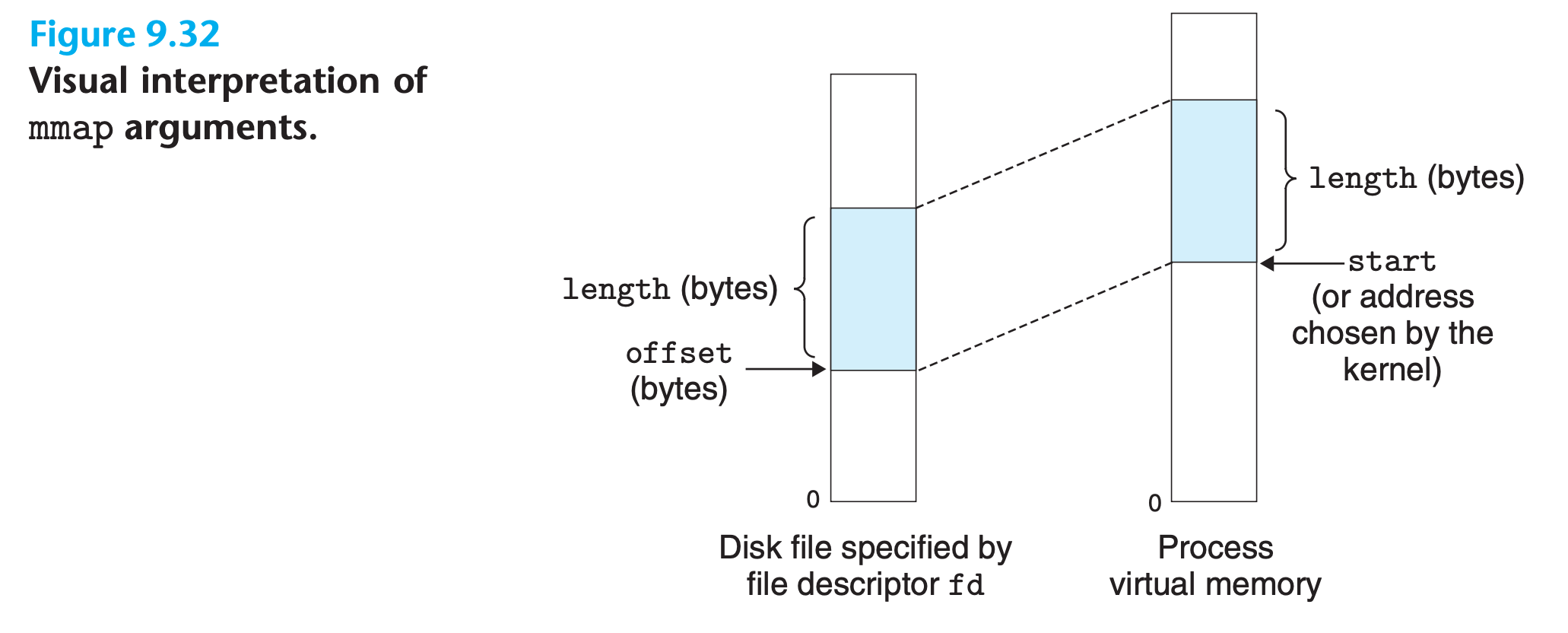
- The
mmapfunction asks the kernel to create a new virtual memory area, preferably one that starts at addressstart, and to map a contiguous chunk of the object specified by file descriptorfdto the new area - The contiguous object chunk has a size of
lengthbytes and starts at anoffsetof offset bytes from the beginning of the file. - The start address is merely a hint(the final decision is made by kernal), and is usually specified as
NULL. - The
protargument contains bits that describe the access permissions of the newly mapped virtual memory area
1 | {PROT_EXEC : "Pages in the area consist of instructions that may be executed by the CPU.", |
- The
flagsargument consists of bits that describe the type of the mapped object.
1 | { |
The munmap function deletes regions of virtual memory:
1 |
|
The munmap function deletes the area starting at virtual address start and consisting of the next length bytes. Subsequent references to the deleted region result in segmentation faults.
Practice Problem 9.5
Write a C program
mmapcopy.cthat usesmmapto copy an arbitrary-size disk file tostdout. The name of the input file should be passed as a command-line argument.
My solution :
1 | //No error checking below |
Modified solution on the book:
1 | //No error checking below |
9.9 Dynamic Memory Allocation
For each process, the kernel maintains a variable brk (pronounced “break”) that points to the top of the heap
An allocator maintains the heap as a collection of various-size blocks.
Allocators come in two basic styles. Both styles require the application to explicitly allocate blocks. They differ about which entity is responsible for freeing allocated blocks.
Explicit allocators : require the application to explicitly free any allocated blocks.(
mallocandfree)Implicit allocators : require the allocator to detect when an allocated block is no longer being used by the program and then free the block.(garbage collectors)
memory allocation is a general idea that arises in a variety of contexts(Not only for manage heap memory)
9.9.1 The malloc and free Functions
1 |
|
The
mallocfunction returns a pointer to a block of memory of at leastsizebytes that is suitably alignedmallocdoes not initialize the memory it returns- Applications that want initialized dynamic memory can use
calloc, a thin wrapper around themalloc - Applications that want to change the size of a previously allocated block can use the
reallocfunction.
- Applications that want initialized dynamic memory can use
1 |
|
The sbrk function grows or shrinks the heap by adding incr to the kernel’s brk pointer
- Calling
sbrkwith a negativeincris legal but tricky because the return value (the old value of brk) points to abs(incr) bytes past the new top of the heap.
1 |
|
The ptr argument must point to the beginning of an allocated block that was obtained from malloc, calloc, or realloc. If not, then the behavior of free is undefined
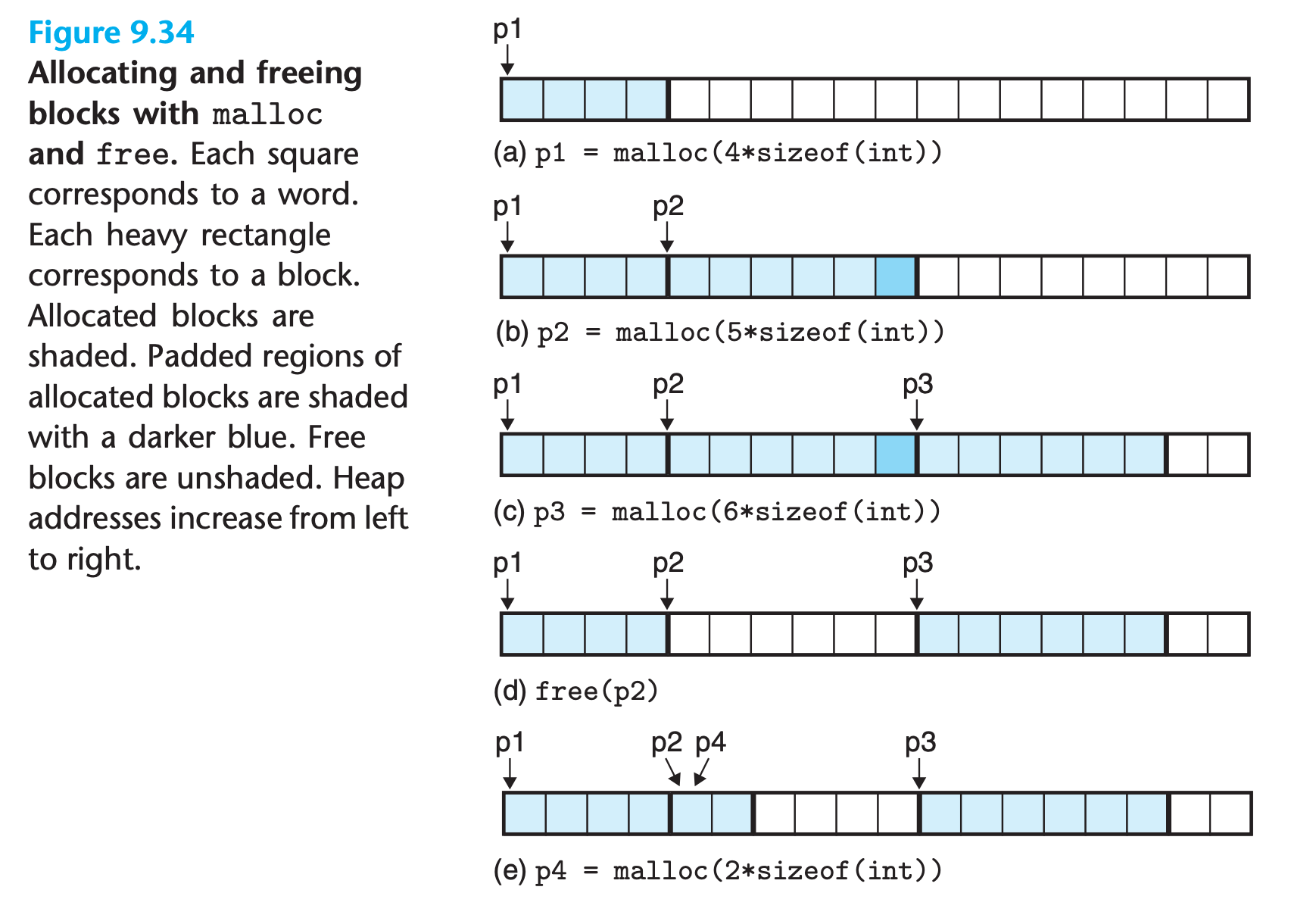
9.9.2 Why Dynamic Memory Allocation?
The most important reason that programs use dynamic memory allocation is that often they do not know the sizes of certain data structures until the program actually runs
9.9.3 Allocator Requirements and Goals
Constraints
Explicit allocators must operate within some rather stringent constraints
- Handling arbitrary request sequences
- An application can make an arbitrary sequence of allocate and free requests
- the allocator cannot make any assumptions about the ordering of allocate and free requests.
- Making immediate responses to requests
- the allocator is not allowed to reorder or buffer requests in order to improve performance.
- Using only the heap
- Aligning blocks (alignment requirement).
- The allocator must align blocks in such a way that they can hold any type of data object
- Not modifying allocated blocks.
- Allocators can only manipulate or change free blocks.
- they are not allowed to modify or move blocks once they are allocated
- techniques such as compaction of allocated blocks are not permitted.
Goals
- Maximizing throughput.
- Maximizing memory utilization
9.9.4 Fragmentation
unused memory is not available to satisfy allocate requests.
There are two forms of fragmentation:
Internal fragmentation
- Internal fragmentation occurs when an allocated block size is larger than the required size
- It is simply the sum of the differences between the sizes of the allocated blocks and their requirements
- Thus, at any point in time, the amount of internal fragmentation depends only on the pattern of previous requests and the allocator implementation.
External fragmentation
External fragmentation occurs when there is enough aggregate free memory to satisfy an allocate request, but no single free block is large enough to handle the request.
Figure 9.34 (e)
External fragmentation is much more difficult to quantify than internal fragmentation because it depends not only on the pattern of previous requests and the allocator implementation but also on the pattern of future requests
9.9.5 Implementation Issues
A practical allocator that strikes a balance between throughput and utilization must consider the following issues:
- Free block organization. How do we keep track of free blocks?
- Placement. How do we choose an appropriate free block in which to place a newly allocated block?
- Splitting. After we place a newly allocated block in some free block, what do we do with the remainder of the free block?
- Coalescing. What do we do with a block that has just been freed?
9.9.6 Implicit Free Lists
Any practical allocator needs some data structure that allows it to distinguish block boundaries and to distinguish between allocated and free blocks.
- Most allocators embed this information in the blocks themselves.
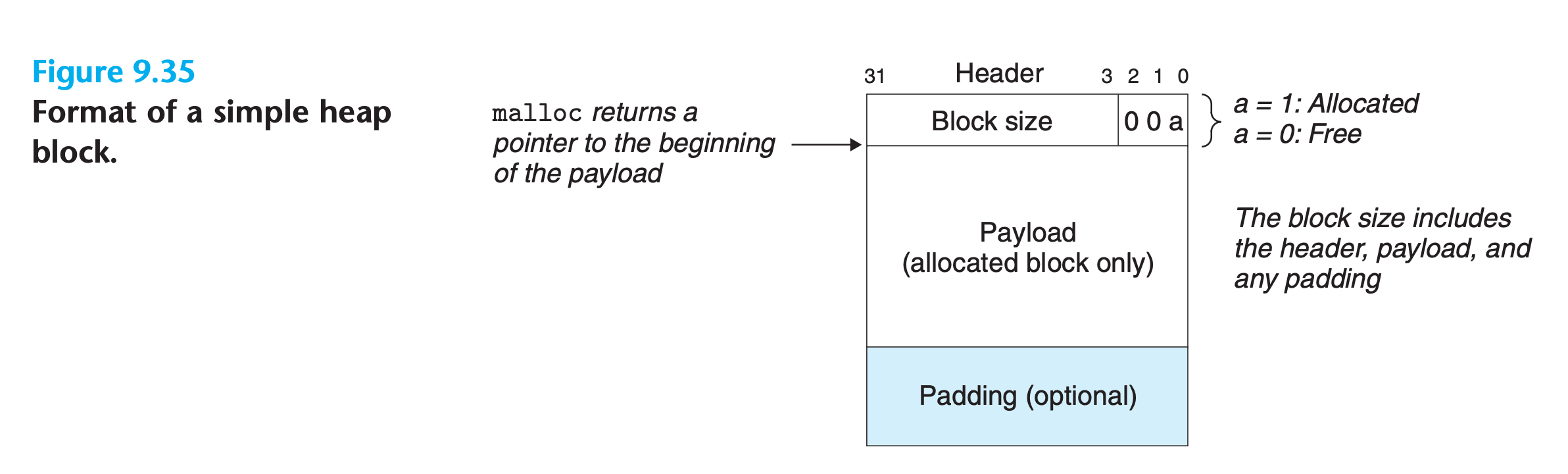
- A significant disadvantage is that the cost of any operation that requires a search of the free list, such as placing allocated blocks, will be linear in the total number of allocated and free blocks in the heap.
- Notice that we need some kind of specially marked end block(size of 0, allocated)
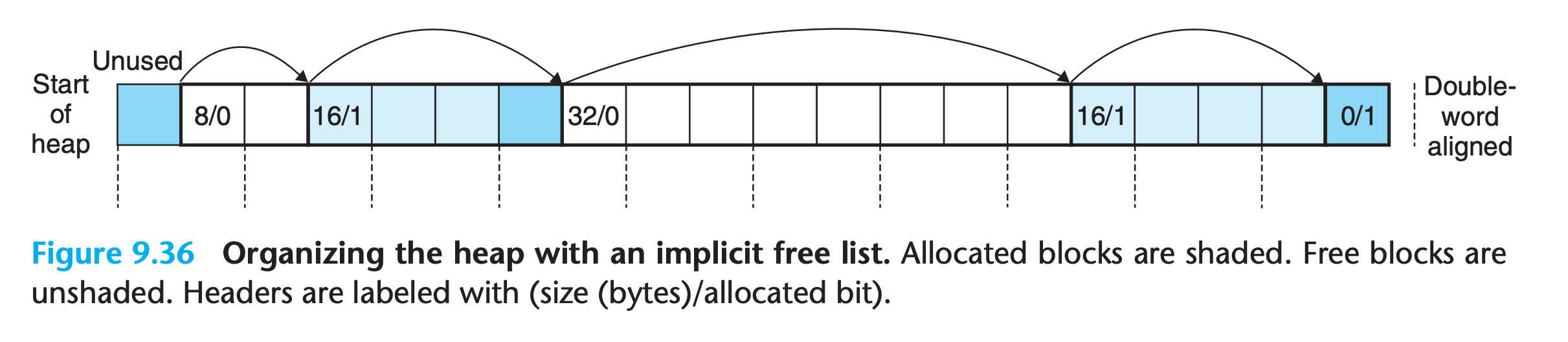
start of the heapmight no be aligned, so we need someunusedblock at the beginning to do the alignment
Practice Problem 9.6
Determine the block sizes and header values that would result from the following sequence of
mallocrequests.Assumptions: (1) The allocator maintains double-word alignment and uses an implicit free list with the block format from Figure 9.35. (2) Block sizes are rounded up to the nearest multiple of 8 bytes.
Request Block size (decimal bytes) Block header (hex) malloc(2) malloc(9) malloc(15) malloc(20)
My solution : :white_check_mark:
1 | '0x{:08x}'.format(blocksize | 1) |
| Request | Block size (decimal bytes) | Block header (hex) |
|---|---|---|
| malloc(2) | 8 | 0x00000009 |
| malloc(9) | 16 | 0x00000011 |
| malloc(15) | 24 | 0x00000019 |
| malloc(20) | 24 | 0x00000019 |
9.9.7 Placing Allocated Blocks
When an application requests a block of k bytes, the allocator searches the free list for a free block that is large enough to hold the requested block. The manner in which the allocator performs this search is determined by the placement policy. Some common policies are first fit, next fit, and best fit.
- First fit searches the free list from the beginning and chooses the first free block that fits
1 | p = start ; //start from the beginning |
- Next fit is similar to first fit, but instead of starting each search at the beginning of the list, it starts each search where the previous search left off.
- Best fit examines every free block and chooses the free block with the smallest size that fits
9.9.8 Splitting Free Blocks
9.9.9 Getting Additional Heap Memory
use sbrk to ask more space from the kernal
9.9.10 Coalescing Free Blocks
To combat false fragmentation, any practical allocator must merge adjacent free blocks in a process known as coalescing.
This raises an important policy decision about when to perform coalescing.
9.9.11 Coalescing with Boundary Tags
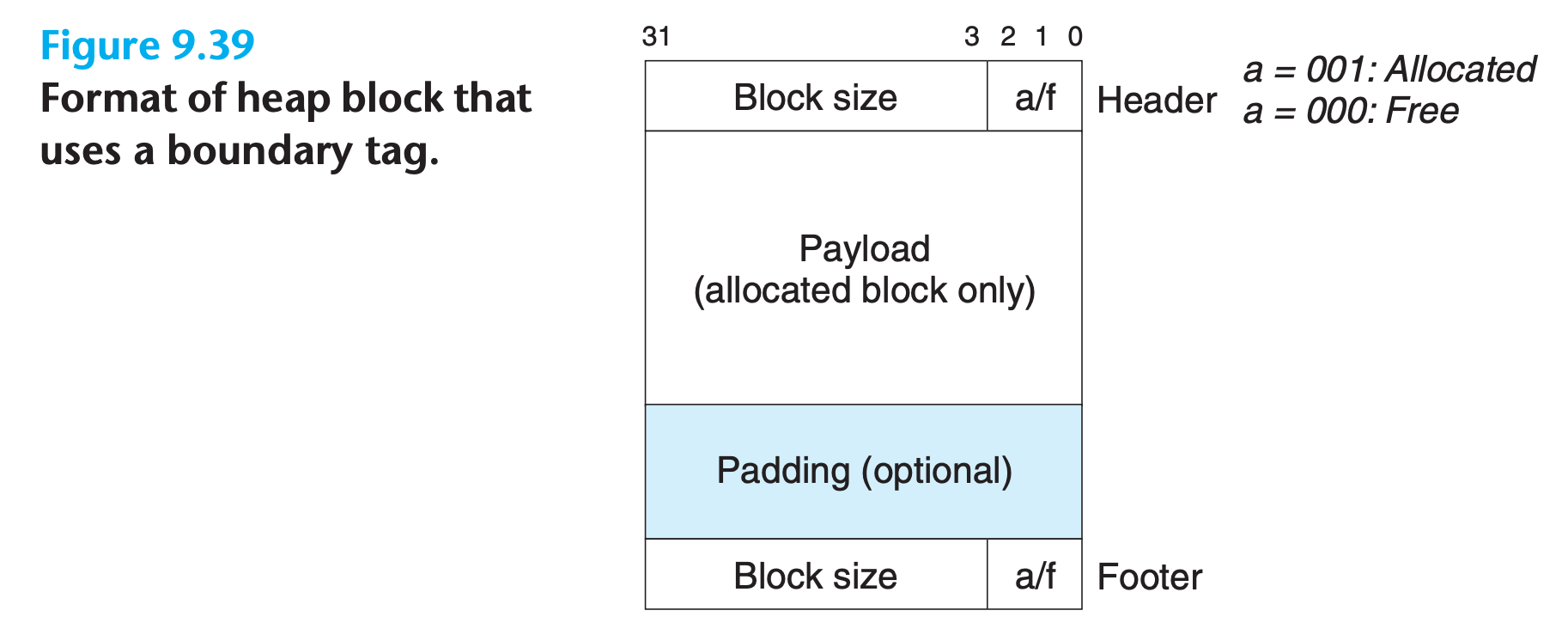
(If we were to store the allocated/free bit of the previous block in one of the excess loworder bits of the current block, then allocated blocks would not need footers, and we could use that extra space for payload. Note, however, that free blocks would still need footers)
(When coalescing free blocks, we always update the first free block’s size)
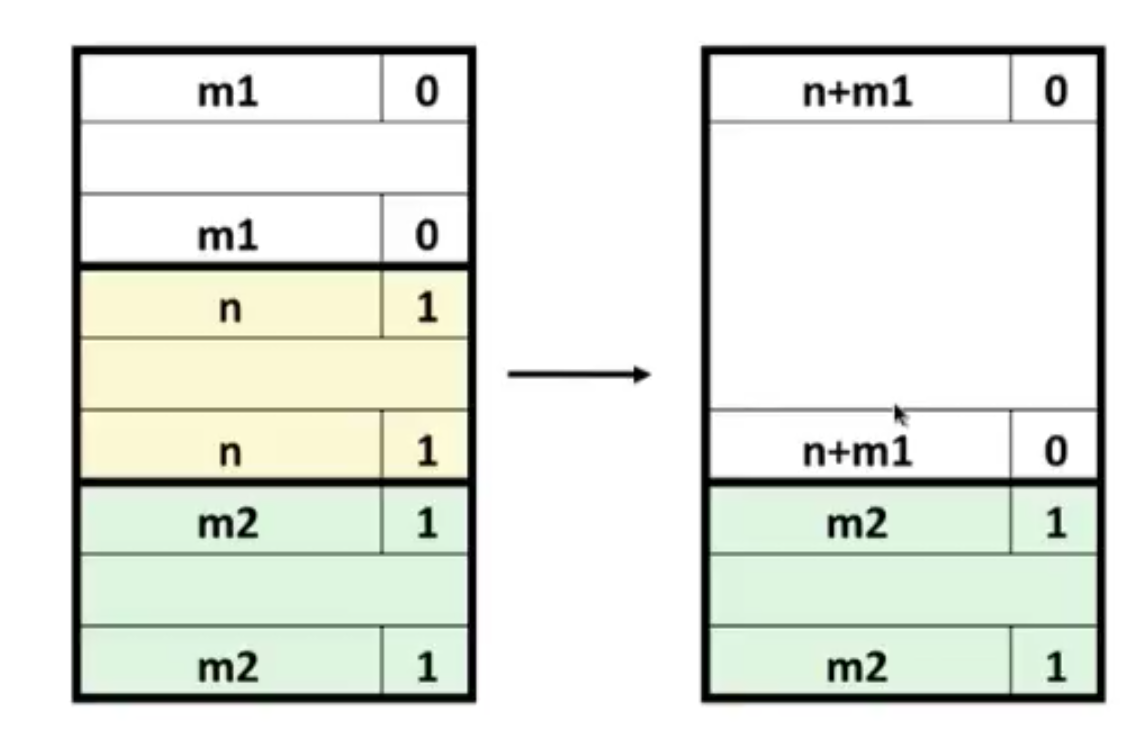
9.9.12 Putting It Together: Implementing a Simple Allocator
Implicit list strategy is not used in malloc and free for the sake of linear time complexity.
9.9.13 Explicit Free Lists
Since by definition the body of a free block is not needed by the program, the pointers that implement the data structure can be stored within the bodies of the free blocks.
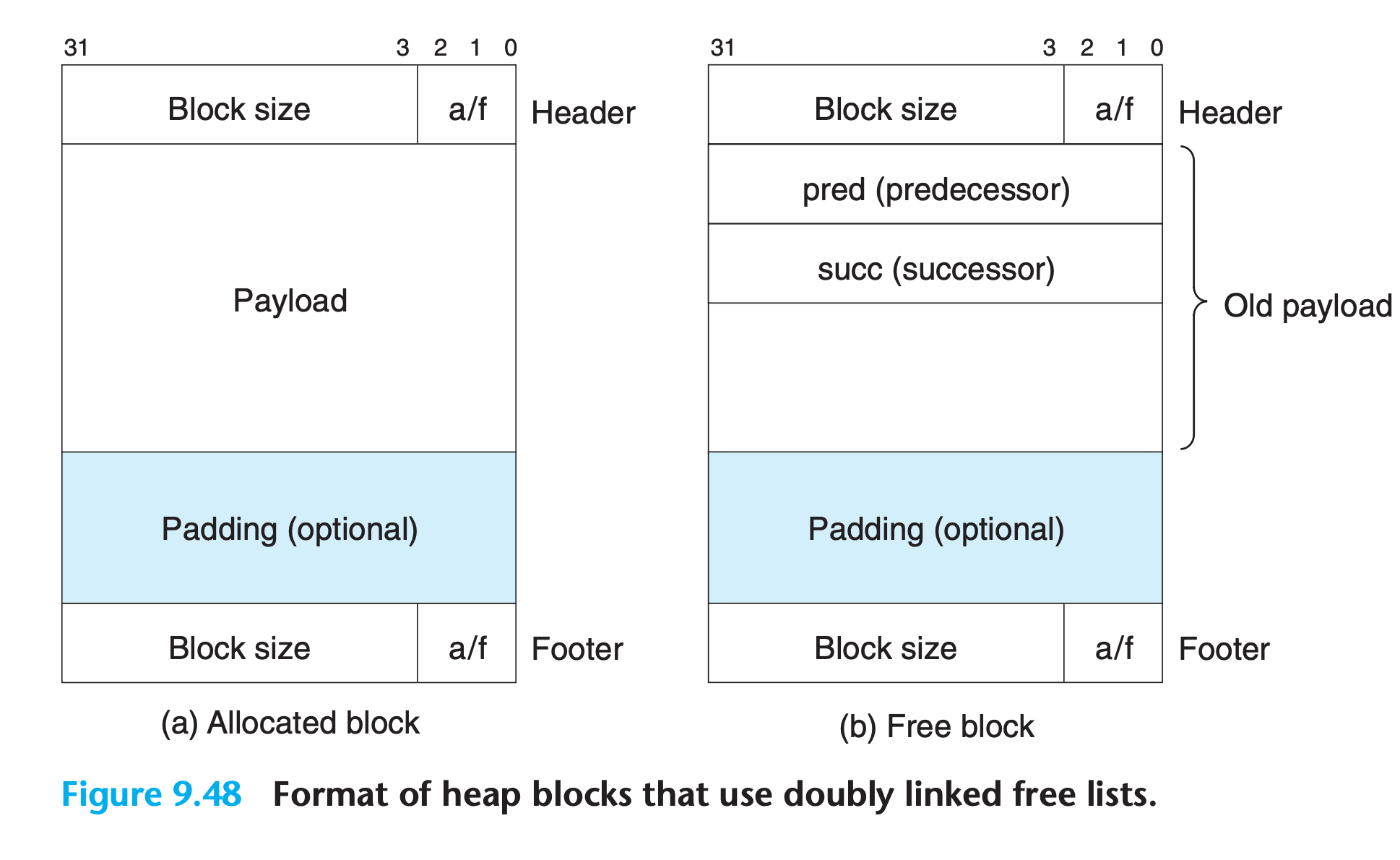
- Using a doubly linked list instead of an implicit free list reduces the first-fit allocation time from linear in the total number of blocks to linear in the number of free blocks.
- A disadvantage of explicit lists in general is that free blocks must be large enough to contain all of the necessary pointers, as well as the header and possibly a footer. This results in a larger minimum block size and increases the potential for internal fragmentation.
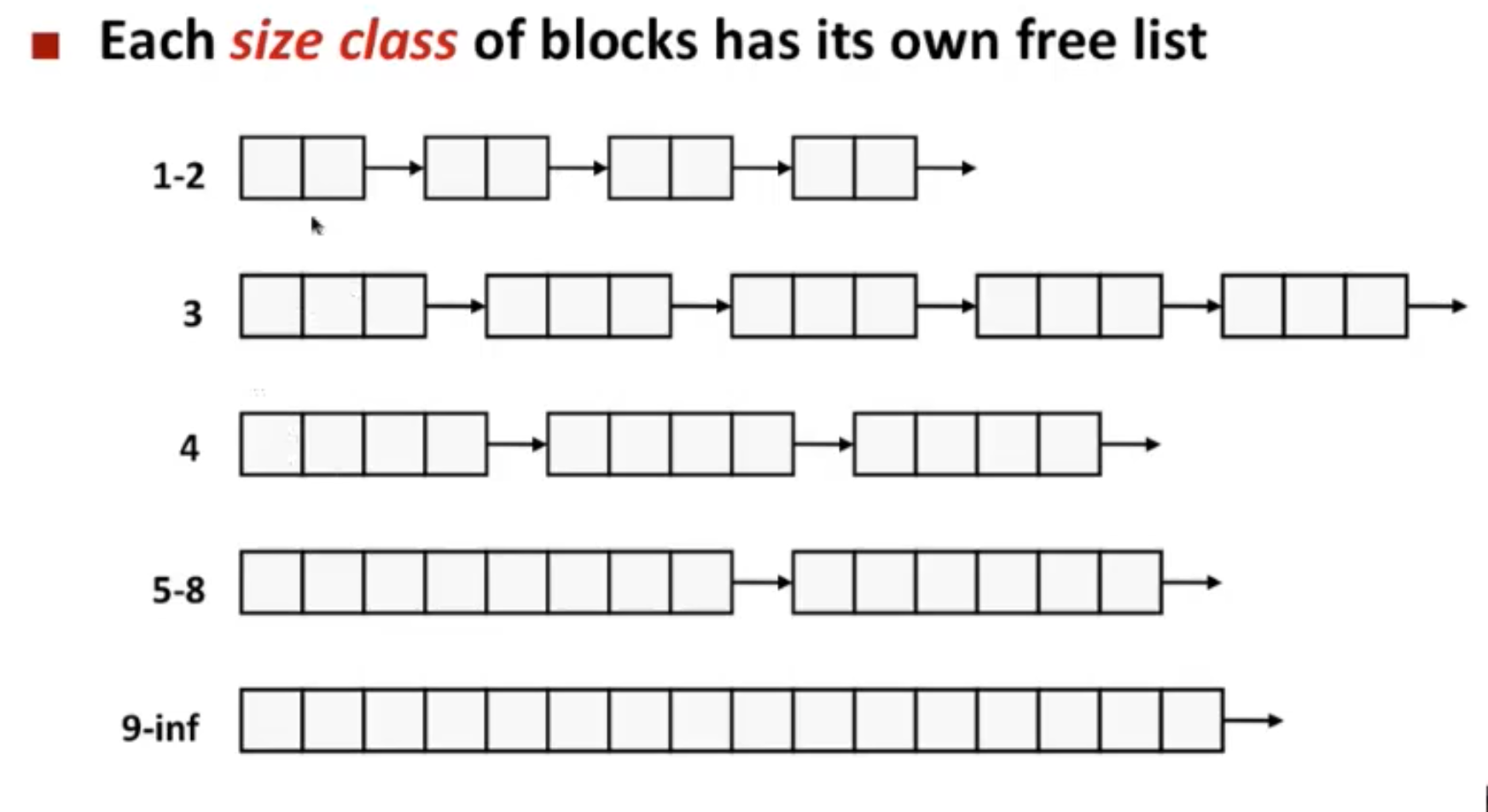
9.9.14 Segregated Free Lists
A popular approach for reducing the allocation time, known generally as segregated storage, is to maintain multiple free lists, where each list holds blocks that are roughly the same size.
For example
1 | # partition the block sizes by powers of 2 |
- The allocator maintains an array of free lists, with one free list per size class, ordered by increasing size
- When the allocator needs a block of size n, it searches the appropriate free list. If it cannot find a block that fits, it searches the next list, and so on.
1 | FreeBlock* lists[N]; |
Simple Segregated Storage
With simple segregated storage, the free list for each size class contains same-size blocks, each the size of the largest element of the size class.
(For example, if some size class is defined as {17–32}, then the free list for that class consists entirely of blocks of size 32)
Segregated Fits
The segregated fits approach is a popular choice with production-quality allocators such as the GNU malloc package provided in the C standard library because it is both fast and memory efficient.
- With this approach, the allocator maintains an array of free lists. Each free list is associated with a size class and is organized as some kind of explicit or implicit list. Each list contains potentially different-size blocks whose sizes are members of the size class
- To allocate a block, we determine the size class of the request and do a firstfit search of the appropriate free list for a block that fits.
- If we find one, then we (optionally) split it and insert the fragment in the appropriate free list.
- If we cannot find a block that fits, then we search the free list for the next larger size class.
- If none of the free lists yields a block that fits, then we request additional heap memory from the operating system, allocate the block out of this new heap memory, and place the remainder in the appropriate size class
- To free a block, we coalesce and place the result on the appropriate free list.
Buddy Systems
A buddy system is a special case of segregated fits where each size class is a power of 2.
- The major advantage of a buddy system allocator is its fast searching and coalescing.
- The major disadvantage is that the power-of-2 requirement on the block size can cause significant internal fragmentation.
9.10 Garbage Collection
A garbage collector is a dynamic storage allocator that automatically frees allocated blocks that are no longer needed by the program
9.10.1 Garbage Collector Basics
A garbage collector views memory as a directed reachability graph of the form shown in Figure 9.49
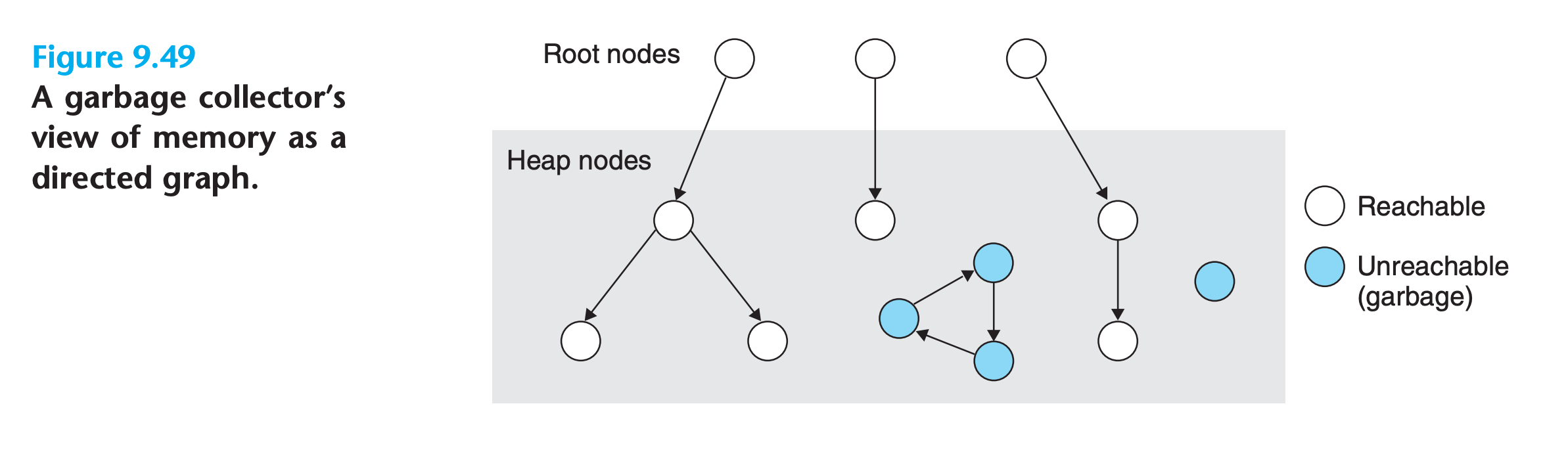
- The nodes of the graph are partitioned into a set of root nodes and a set of heap nodes
- Each heap node corresponds to an allocated block in the heap.
- A directed edge
p → qmeans that some location in block p points to some location in block q - Root nodes correspond to locations not in the heap that contain pointers into the heap. These locations can be registers, variables on the stack, or global variables in the read/write data area of virtual memory
- We say that a node p is reachable if there exists a directed path from any root node to p
- The role of a garbage collector is to maintain some representation of the reachability graph and periodically reclaim the unreachable nodes by freeing them and returning them to the free list.
Collectors can provide their service on demand, or they can run as separate threads in parallel with the application, continuously updating the reachability graph and reclaiming garbage.
9.10.2 Mark&Sweep Garbage Collectors
A Mark&Sweep garbage collector consists of a mark phase, which marks all reachable and allocated descendants of the root nodes, followed by a sweep phase, which frees each unmarked allocated block.
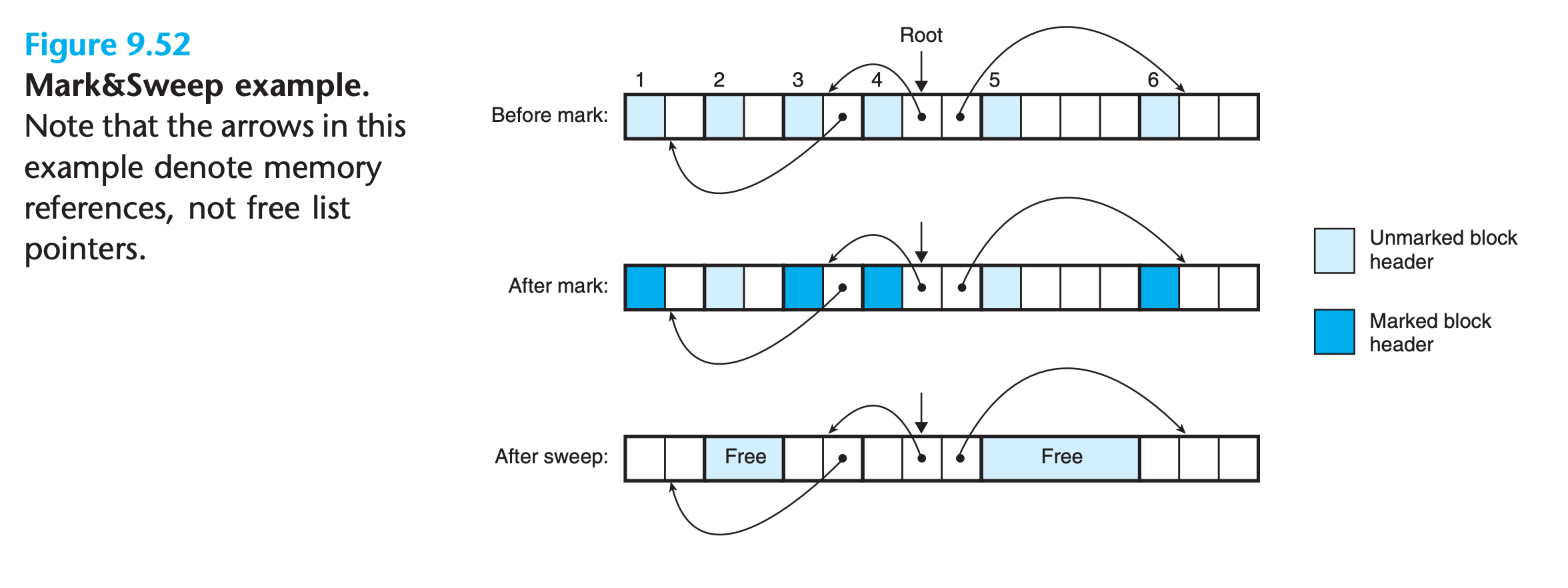
9.10.3 Conservative Mark&Sweep for C Programs
Since C does not tag memory locations with any type information(No way to determine if the data is a pointer or not), the algorithm have to be conservative.
9.11 Common Memory-Related Bugs in C Programs
9.11.1 Dereferencing Bad Pointers
9.11.2 Reading Uninitialized Memory
A common error is to assume that heap memory is initialized to zero
9.11.3 Allowing Stack Buffer Overflows
9.11.4 Assuming That Pointers and the Objects They Point to Are the Same Size
9.11.5 Making Off-by-One Errors
9.11.6 Referencing a Pointer Instead of the Object It Points To
9.11.7 Misunderstanding Pointer Arithmetic
9.11.8 Referencing Nonexistent Variables
9.11.9 Referencing Data in Free Heap Blocks
9.11.10 Introducing Memory Leaks
9.12 Summary
