Network Programming
Interestingly, all network applications are based on the same basic programming model, have similar overall logical structures, and rely on the same programming interface.
11.1 The Client-Server Programming Model
Every network application is based on the client-server model.
The fundamental operation in the client-server model is the transaction
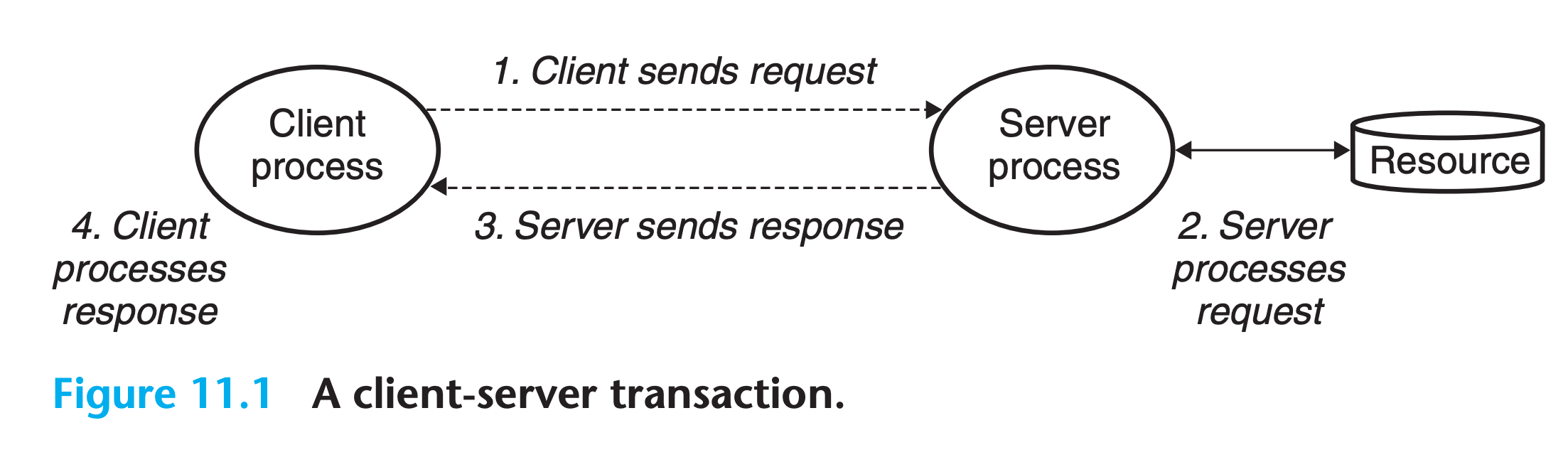
A client-server transaction consists of four steps:
- When a client needs service, it initiates a transaction by sending a request to the server. For example, when a Web browser needs a file, it sends a request to a Web server.
- The server receives the request, interprets it, and manipulates its resources in the appropriate way. For example, when a Web server receives a request from a browser, it reads a disk file.
- The server sends a response to the client and then waits for the next request. For example, a Web server sends the file back to a client.
- The client receives the response and manipulates it. For example, after a Web browser receives a page from the server, it displays it on the screen.
It is important to realize that clients and servers are processes and not machines, or hosts as they are often called in this context !!!
A single host can run many different clients and servers concurrently, and a client and server transaction can be on the same or different hosts. The client-server model is the same, regardless of the mapping of clients and servers to hosts.
11.2 Networks
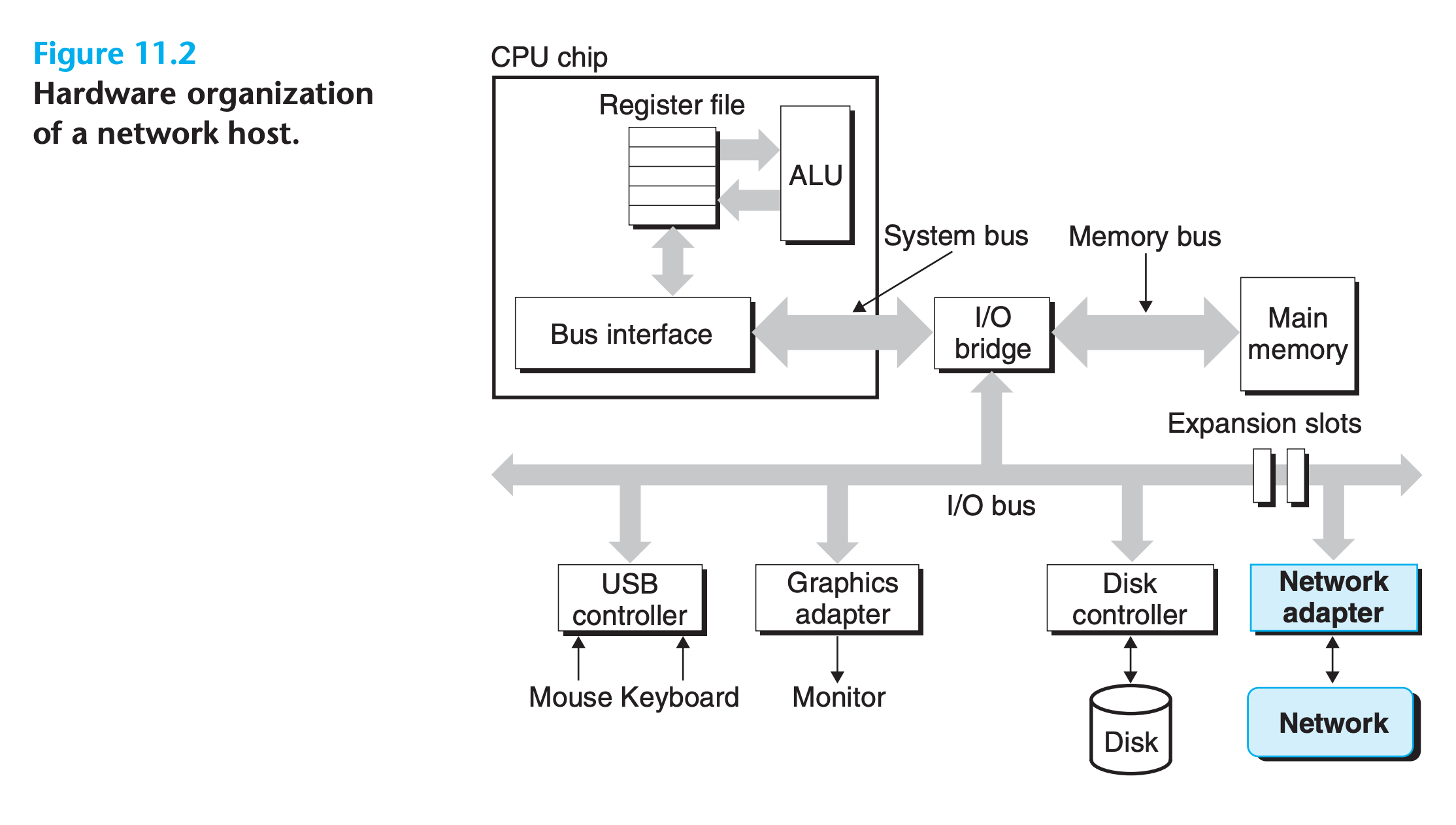
To a host, a network is just another I/O device that serves as a source and sink for data
11.3 The Global IP Internet
- check your host ip(Linux only)
1 | $ hostname -i |
- Store IP address
1 | struct in_addr{ |
- Convert to network endian
1 |
|
- Application programs can convert back and forth between IP addresses and dotted-decimal strings using the functions
inet_ptonandinet_ntop.
1 |
|
Practice Problem 11.1
Complete the following table:
2
3
4
5
6
7
8
9
"Dotted-decimal address":"Hex address",
"107.212.122.205" :
"64.12.149.13" :
"107.212.96.29" :
"" : 0x00000080,
"" : 0xFFFFFF00,
"" : 0x0A010140
}
My solution: :white_check_mark:
1 |
|
1 | $ ./net |
Be fxxking careful when processing network data, any data on host is host-endian !!!!
11.3.2 Internet Domain Names
The set of domain names forms a hierarchy, and each domain name encodes its position in the hierarchy
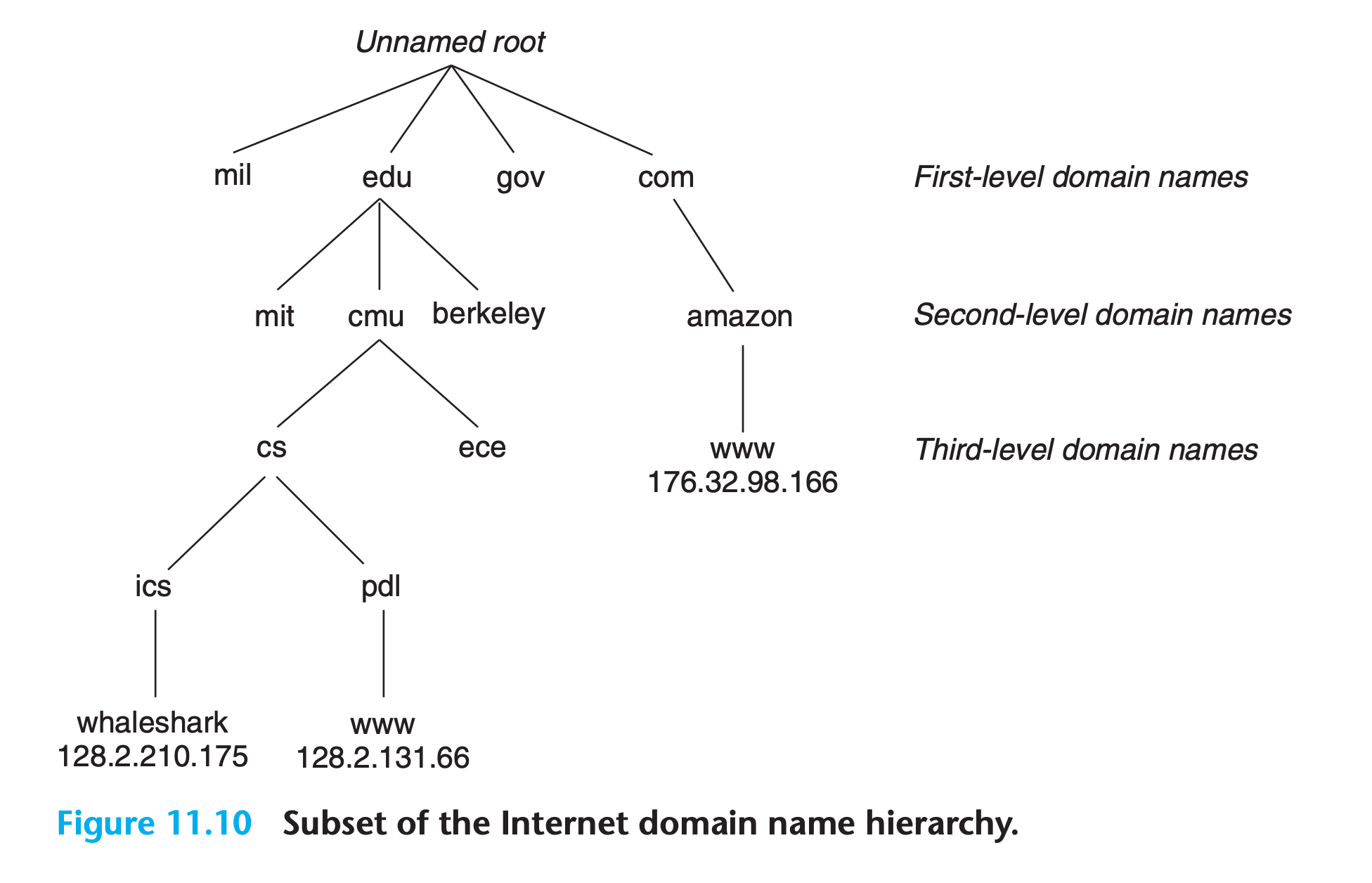
- The nodes of the tree represent domain names that are formed by the path back to the root. Subtrees are referred to as subdomains.
11.3.3 Internet Connections
Internet clients and servers communicate by sending and receiving streams of bytes over connections
A connection is point-to-point in the sense that it connects a pair of processes.
It is full duplex in the sense that data can flow in both directions at the same time
And it is reliable in the sense that—barring some catastrophic failure such as a cable cut by the proverbial careless backhoe operator—the stream of bytes sent by the source process is eventually received by the destination process in the same order it was sent
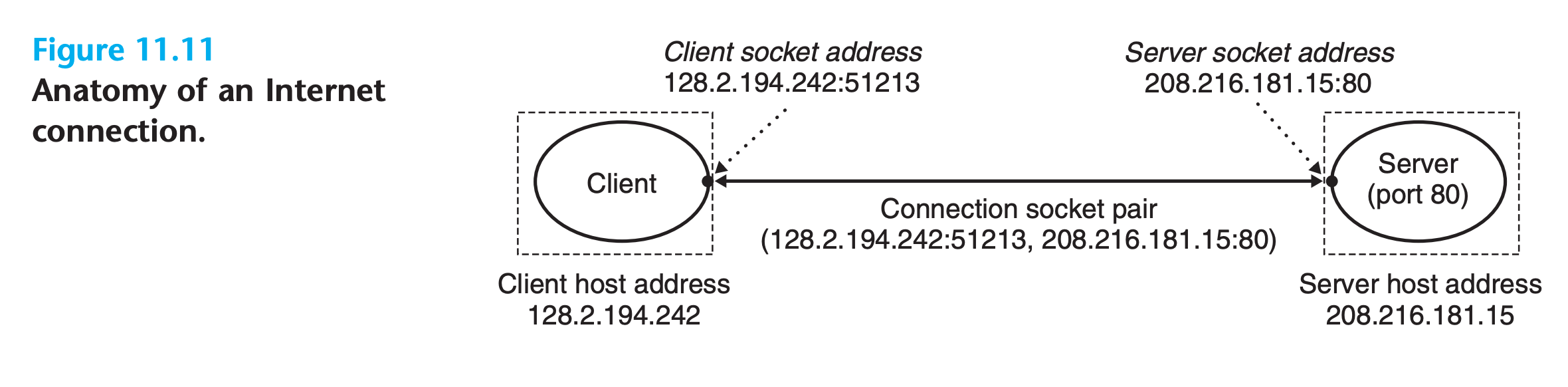
A socket is an end point of a connection.
- Each socket has a corresponding socket address that consists of an Internet address and a 16-bit integer port and is denoted by the notation
address:port. - The port in the client’s socket address is assigned automatically by the kernel when the client makes a connection request and is known as an ephemeral port.
- The mapping between well-known names and well-known ports is contained in a file called
/etc/services.(http->80 , https->443)
- Each socket has a corresponding socket address that consists of an Internet address and a 16-bit integer port and is denoted by the notation
A connection is uniquely identified by the socket addresses of its two end points. This pair of socket addresses is known as a socket pair and is denoted by the tuple
(cliaddr:cliport, servaddr:servport)
11.4 The Sockets Interface
The sockets interface is a set of functions that are used in conjunction with the Unix I/O functions to build network applications
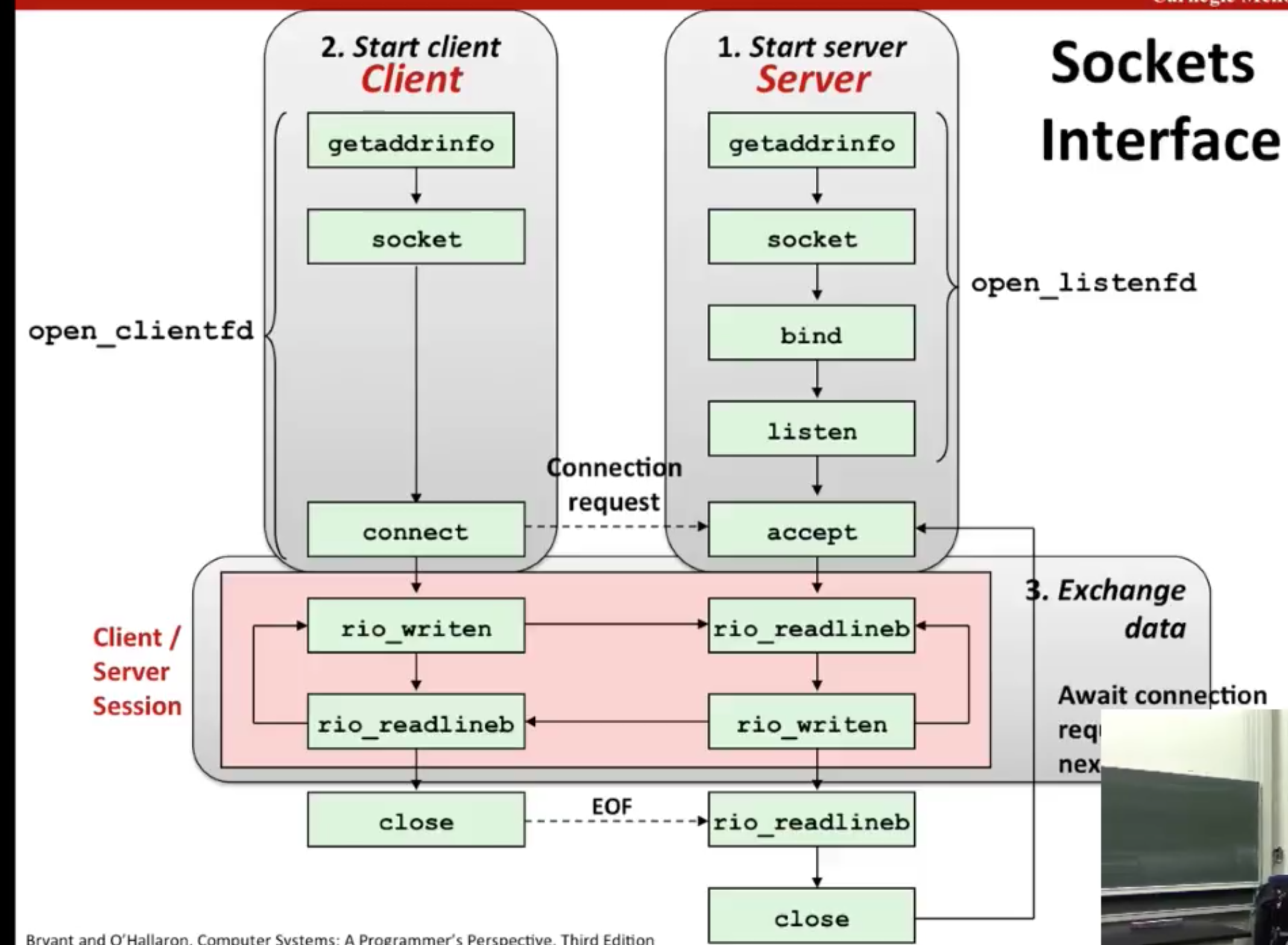
11.4.1 Socket Address Structures
From the perspective of the Linux kernel, a socket is an end point for communication.
From the perspective of a Linux program, a socket is an open file with a corresponding descriptor
1 | /* IP socket address structure */ |
11.4.2 The socket Function
Clients and servers use the socket function to create a socket descriptor.
1 |
|
- The clientfd descriptor returned by socket is only partially opened and cannot yet be used for reading and writing.
- How we finish opening the socket depends on whether we are a client or a server
11.4.3 The connect Function
A client establishes a connection with a server by calling the connect function
1 |
|
The connect function attempts to establish an Internet connection with the server at socket address addr, where addrlen is
sizeof(sockaddr_in)The connect function blocks until either the connection is successfully established or an error occurs.
As with socket, the best practice is to use
getaddrinfoto supply the arguments to connect
11.4.4 The bind Function
The remaining sockets functions—bind, listen, and accept—are used by servers to establish connections with clients.
1 |
|
The bind function asks the kernel to associate the server’s socket address in addr with the socket descriptor sockfd. The addrlen argument is sizeof(sockaddr_ in)
11.4.5 The listen Function
By default, the kernel assumes that a descriptor created by the socket function corresponds to an active socket that will live on the client end of a connection. A server calls the listen function to tell the kernel that the descriptor will be used by a server instead of a client.
1 |
|
- The listen function converts sockfd from an active socket to a listening socket that can accept connection requests from clients.
- The
backlogargument is a hint about the number of outstanding connection requests that the kernel should queue up before it starts to refuse requests
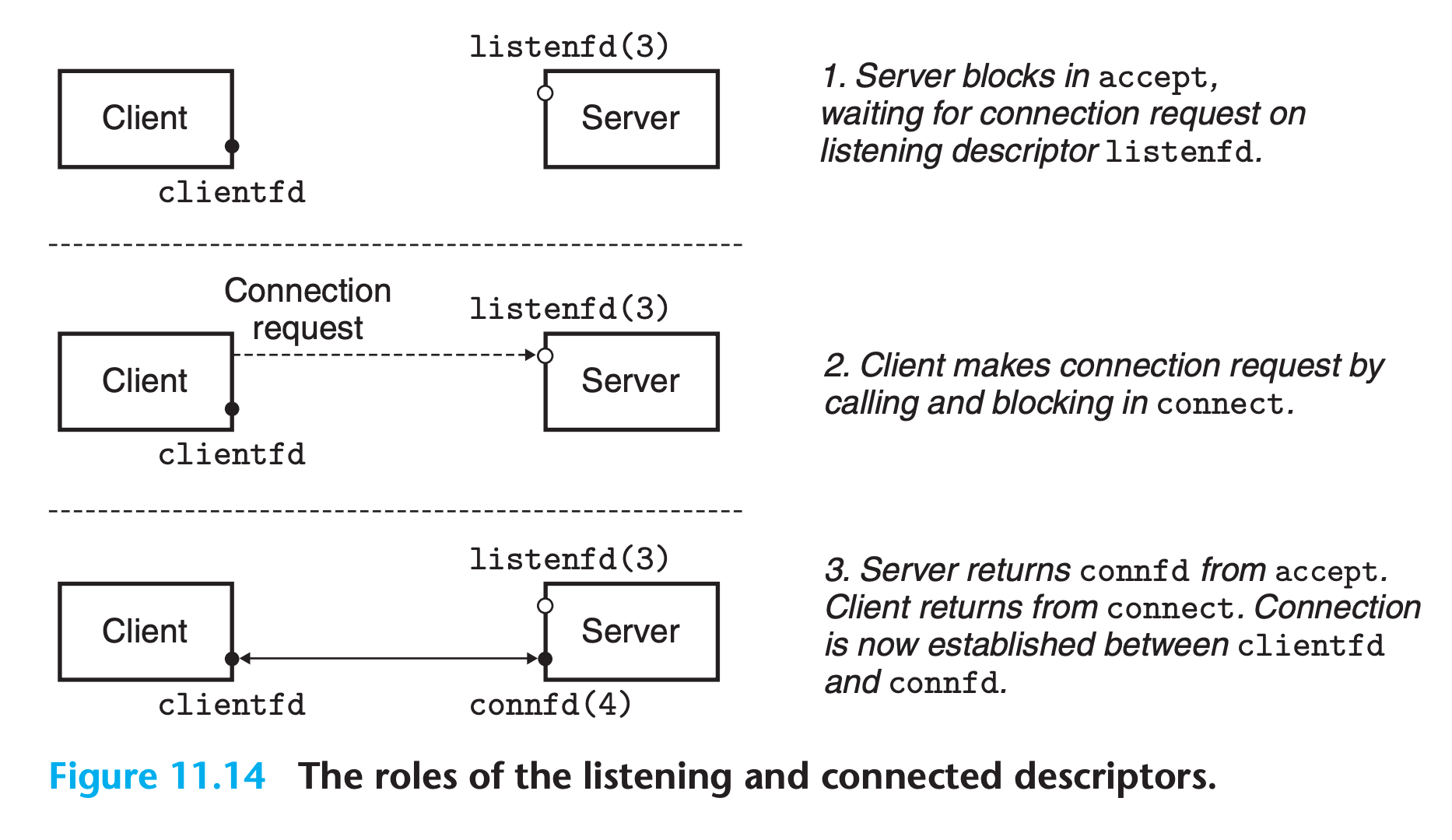
11.4.6 The accept Function
Servers wait for connection requests from clients by calling the accept function.
1 |
|
Why two different fd?
Because as a server, we want to serve multiple client simultaneously.
- The server use the
listenfdto accept connection. - Then use the
connfdcreated byaccept()to communicate with the server. - Same port, same process, but different server.
11.4.7 Host and Service Conversion
- Linux provides some powerful functions, called
getaddrinfoandgetnameinfo, for converting back and forth between binary socket address structures and the string representations of hostnames, host addresses, service names, and port numbers. - When used in conjunction with the sockets interface, they allow us to write network programs that are independent of any particular version of the IP protocol.
The getaddrinfo Function
(Actually invoke DNS to do the job)
The getaddrinfo function converts string representations of hostnames, host addresses, service names, and port numbers into socket address structures
1 |
|
- Given host and service (the two components of a socket address), getaddrinfo returns a result that points to a linked list of addrinfo structures, each of which points to a socket address structure that corresponds to host and service
- After a client calls getaddrinfo, it walks this list, trying each socket address in turn until the calls to socket and connect succeed and the connection is established(Similar for server side)
- To avoid memory leaks, the application must eventually free the list by calling freeaddrinfo
- If getaddrinfo returns a nonzero error code, the application can call gai_strerror to convert the code to a message string.
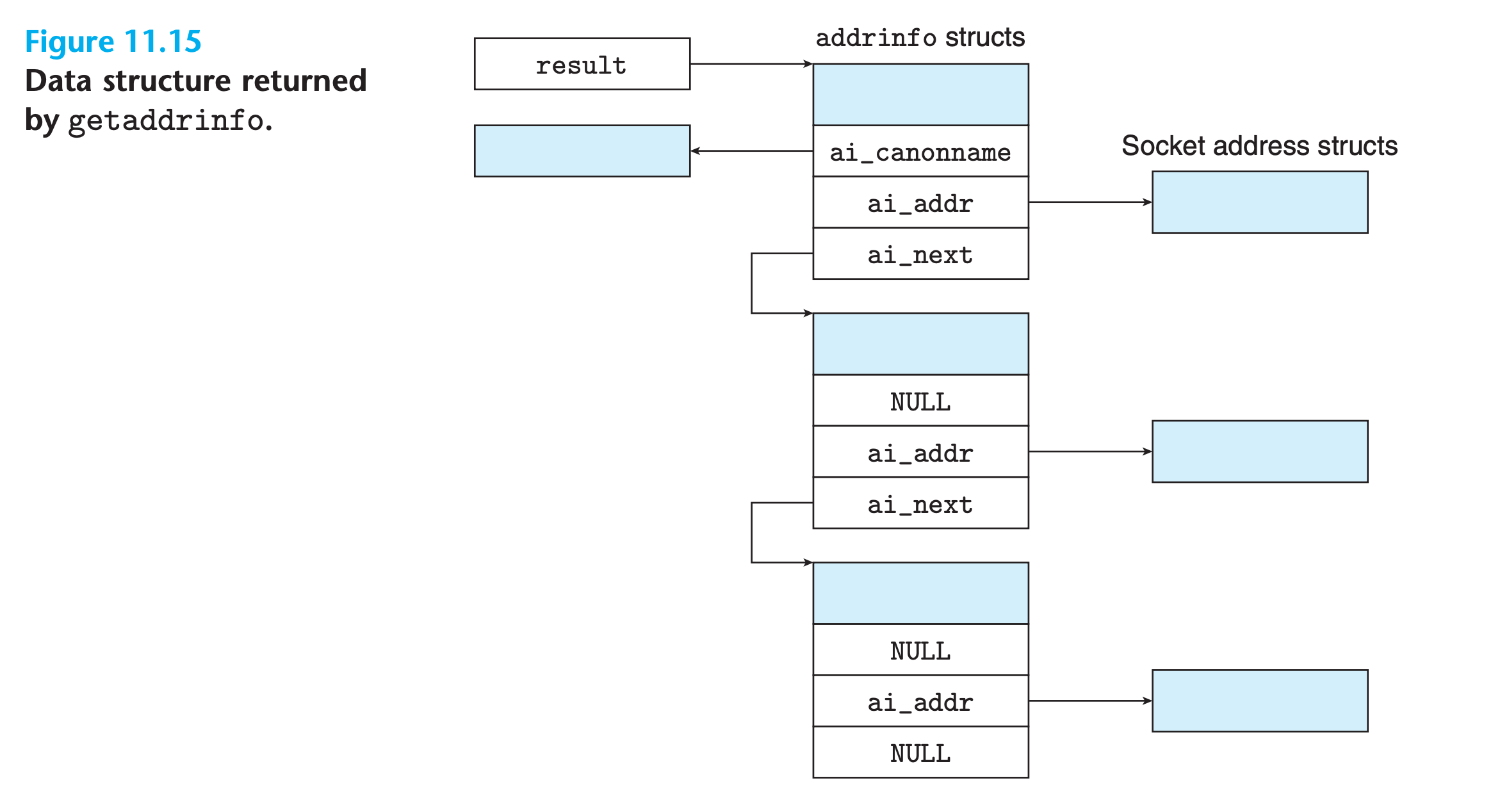
- The optional hints argument is an addrinfo structure (Figure 11.16) that provides finer control over the list of socket addresses that getaddrinfo returns.
Structure of list element
1 | struct addrinfo { |
The getnameinfo Function
The getnameinfo function is the inverse of getaddrinfo. It converts a socket address structure to the corresponding host and service name strings.
1 |
|
11.4.9 Example Echo Client and Server
The best way to learn the sockets interface is to study example code
Echo Client
1 |
|
1 |
|
Test your server:
1 | $ telnet localhost 15213 |
Notice that telnet is quite unsecure, you should NEVER use it in real life!!!
11.5 Web Servers
11.5.1 Web Basics
11.5.2 Web Content
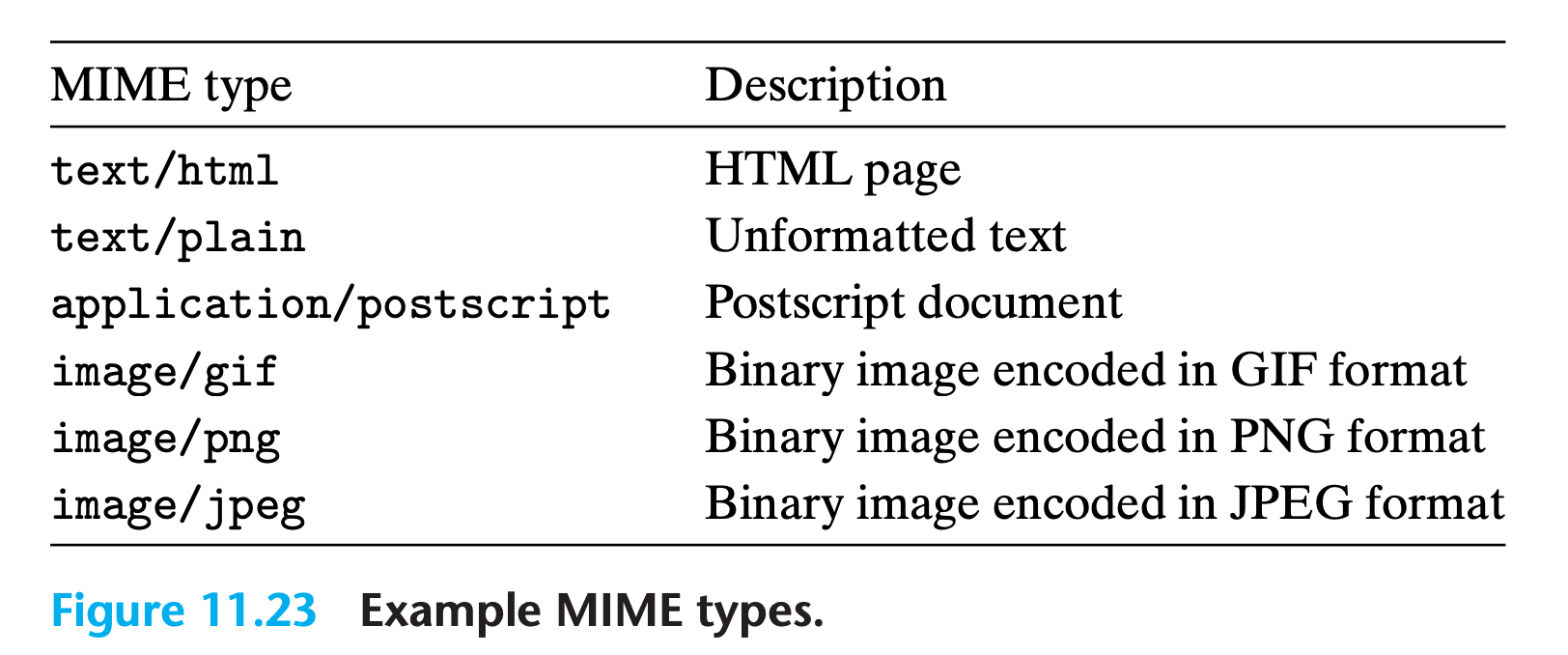
To Web clients and servers, content is a sequence of bytes with an associated MIME (multipurpose internet mail extensions) type.
Web servers provide content to clients in two different ways:
(Deprecated! Nowadays we have client side programming language like javascript executing code in browser to interact with server)
Fetch a disk file and return its contents to the client.
(The disk file is known as static content and the process of returning the file to the client is known as serving static content.)
Run an executable file and return its output to the client.
(The output produced by the executable at run time is known as dynamic content, and the process of running the program and returning its output to the client is known as serving dynamic content.)
Every piece of content returned by a Web server is associated with some file that it manages. Each of these files has a unique name known as a URL
URLs for executable files can include program arguments after the filename. A
?character separates the filename from the arguments, and each argument is separated by an&character.- For example,
http://bluefish.ics.cs.cmu.edu:8000/cgi-bin/adder?15000&213specify an executable file and give it two arguments
- For example,
Clients and servers use different parts of the URL during a transaction.
- Client use prefix like
http://www.google.com:80to determine what kind of server to contact, where the server is, and what port it is listening on. - Server use the suffix like
/index.htmlto find the file on its filesystem and to determine whether the request is for static or dynamic content.
- Client use prefix like
how servers interpret the suffix of a URL
- There are no standard rules for determining whether a URL refers to static or dynamic content.
- Each server has its own rules for the files it manages.
- A classic (old-fashioned) approach is to identify a set of directories, such as cgi-bin, where all executables must reside
- The initial
/in the suffix does NOT denote the Linux root directory- Rather, it denotes the home directory for whatever kind of content is being requested.
- For example, a server might be configured so that all static content is stored in directory
/usr/httpd/htmland all dynamic content is stored in directory/usr/httpd/cgi-bin. - The minimal URL suffix is the
/character, which all servers expand to some default home page such as/index.html. - This explains why it is possible to fetch the home page of a site by simply typing a domain name to the browser. The browser appends the missing
/to the URL and passes it to the server, which expands the/to some default filename.
11.5.3 HTTP Transactions
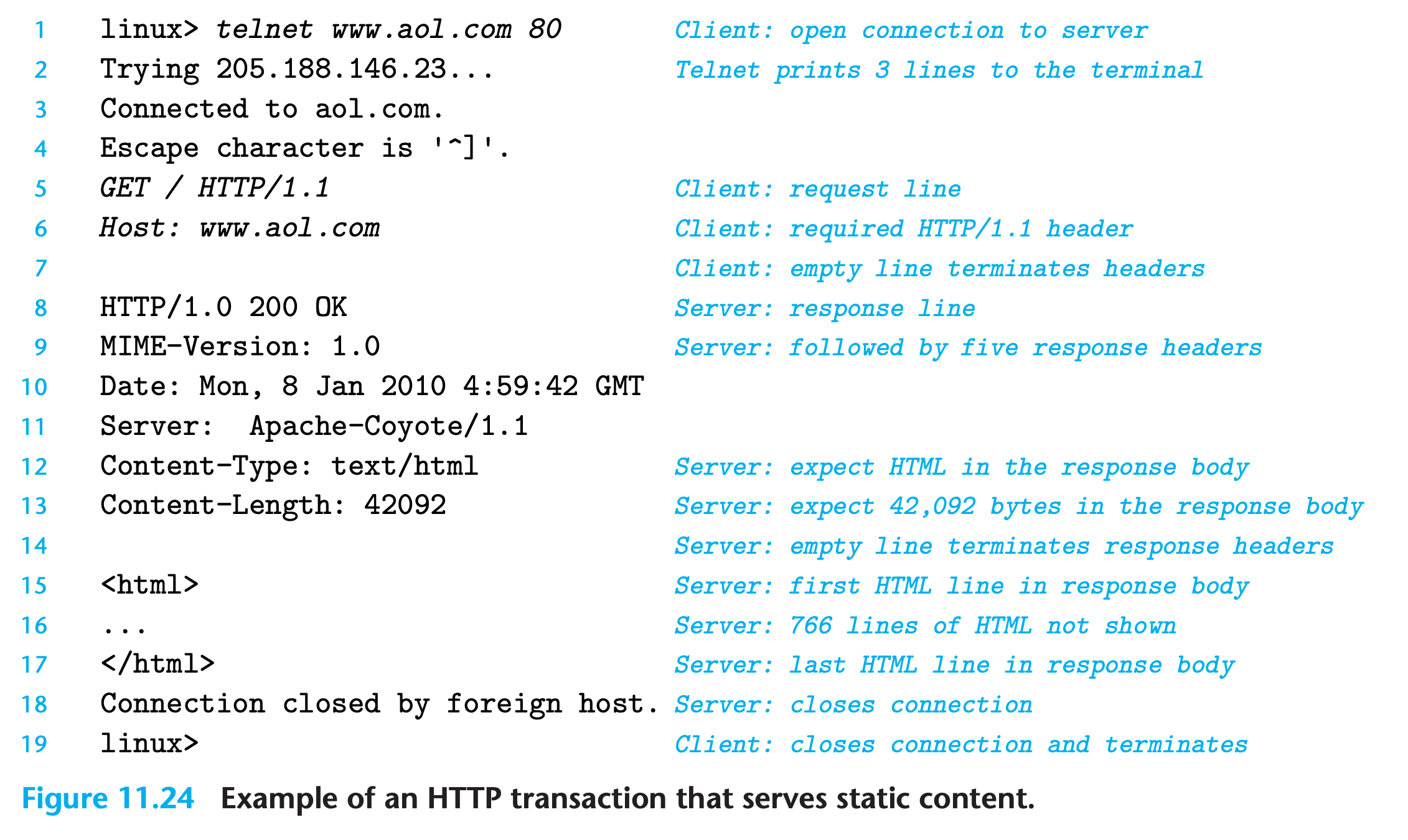
HTTP Requests
An HTTP request consists of
- a request line
- A request line has the form
method URI version - HTTP supports a number of different methods, including
GET, POST, OPTIONS, HEAD, PUT, DELETE, andTRACE
- A request line has the form
- followed by zero or more request headers
- Request headers provide additional information to the server, such as the brand name of the browser or the MIME types that the browser understands.
header-name: header-data
- followed by an empty text line that terminates the list of headers
HTTP Responses

An HTTP response consists of
- a response line
- A response line has the form
version status-code status-message
- A response line has the form
- followed by zero or more response headers
- followed by an empty line that terminates the headers
- followed by the response body
11.5.4 Serving Dynamic Content
If we stop to think for a moment how a server might provide dynamic content to a client, lots of questions arise, and there is a solutio call CGI(Common Gateway Interface)
How Does the Client Pass Program Arguments to the Server?
Arguments for GET requests are passed in the URI. As we have seen, a ‘?’ character separates the filename from the arguments, and each argument is separated by an ‘&’ character
How Does the Server Pass Arguments to the Child?
After a server receives a request such as GET /cgi-bin/adder?15000&213 HTTP/1.1,it calls fork to create a child process and calls execve to run the /cgi-bin/adder program in the context of the child. Programs like the adder program are often referred to as CGI programs because they obey the rules of the CGI standard. Before the call to execve, the child process sets the CGI environment variable QUERY_STRING to 15000&213, which the adder program can reference at run time using the Linux getenv function.
How Does the Server Pass Other Information to the Child?
CGI defines a number of other environment variables that a CGI program can expect to be set when it runs

Where Does the Child Send Its Output?
A CGI program sends its dynamic content to the standard output.
Before the child process loads and runs the CGI program, it uses the Linux dup2 function to redirect standard output to the connected descriptor that is associated with the client. Thus, anything that the CGI program writes to standard output goes directly to the client.
Notice that since the parent does not know the type or size of the content that the child generates, the child is responsible for generating the Content-type and Content-length response headers, as well as the empty line that terminates the headers