Beautiful internal design mode and somewhere ugly interface
Concept
File struct
1 2 3 4 5 6 7 8 9
$ tree GitRepository GitRepository ├── bar.txt └── foo └── bar.txt # a fold is called a `tree` # a file is called a `blob` # an "entire copy" of the root tree(the whole GitRepository folder) is called a `snapshot` or a `commit` # `snapshot` also include some metadata like author, date and optional description
Mode of history
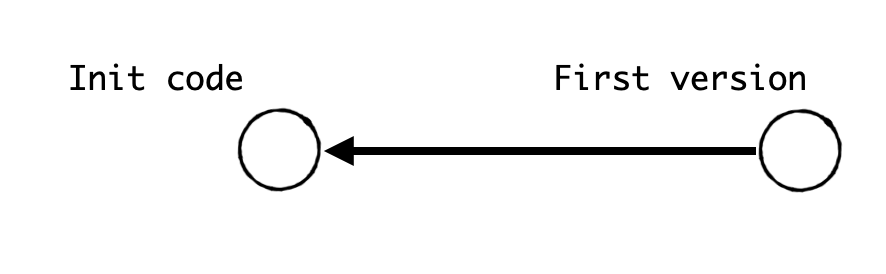
Instead of a linear sequence of snapshots, Git use a directed acyclic graph to mode history
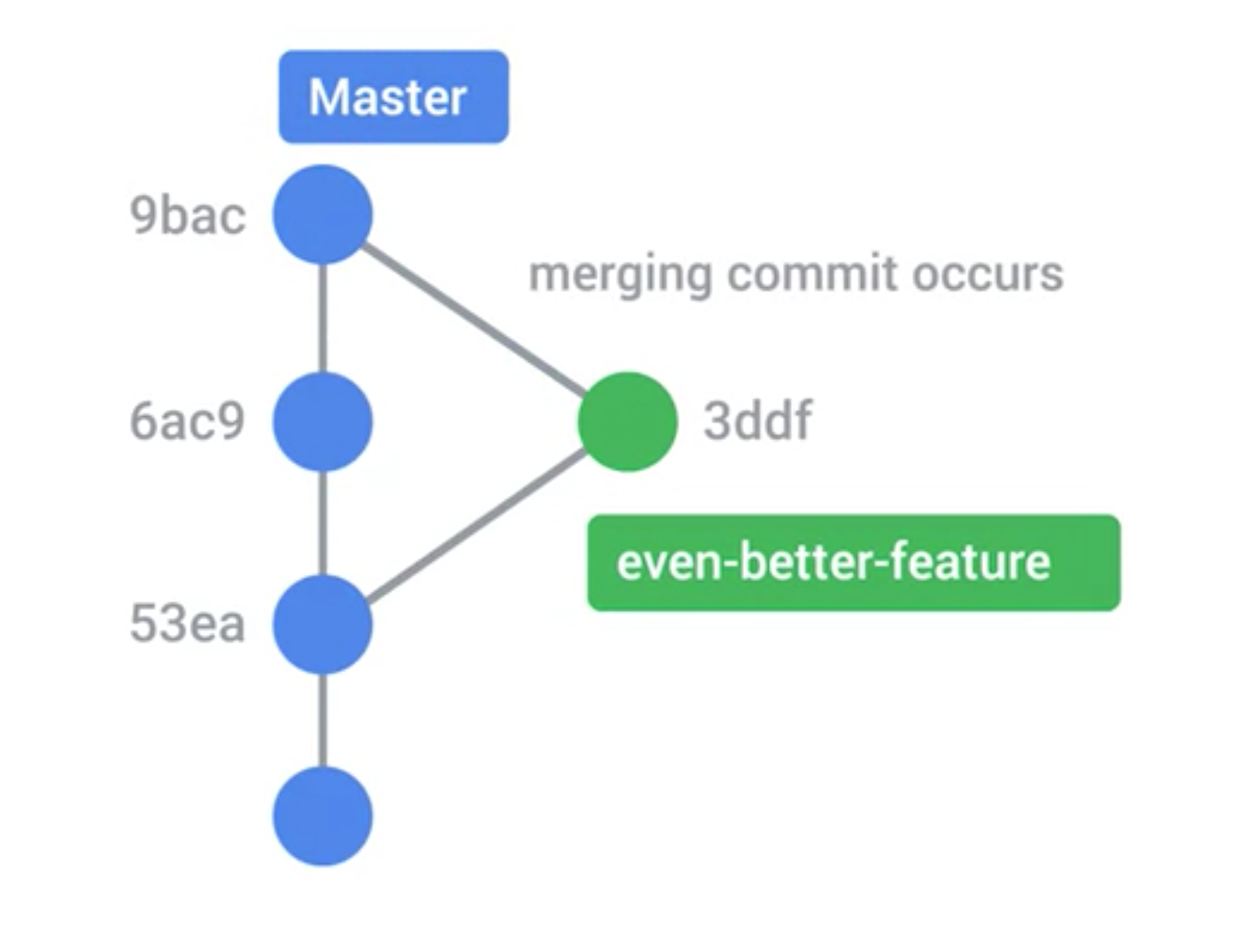
A dot is a snapshot
Arrow means one snapshot based on the pointed snapshot. In other word, Init code developped into First version, Init code is First version’s precedent
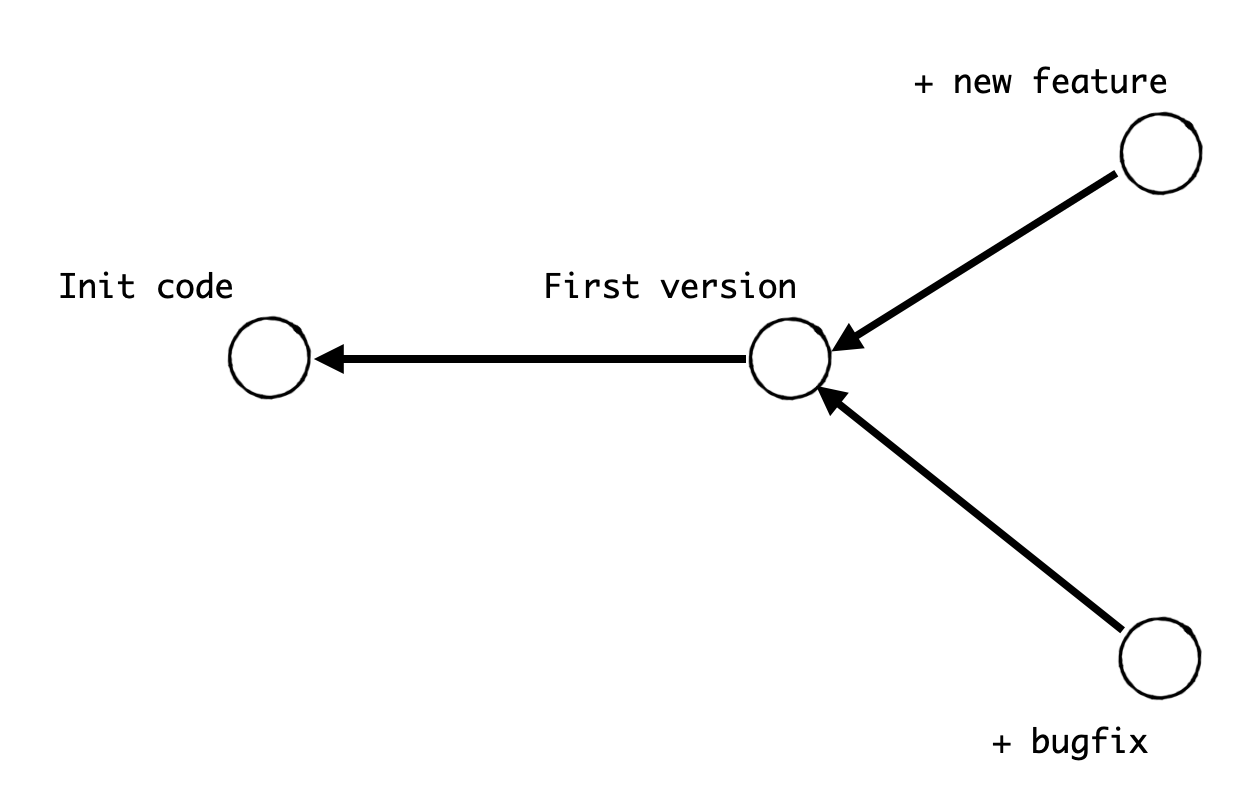
two different version based on one same version are called branches
They share the same code of First version, but both have their own unique code
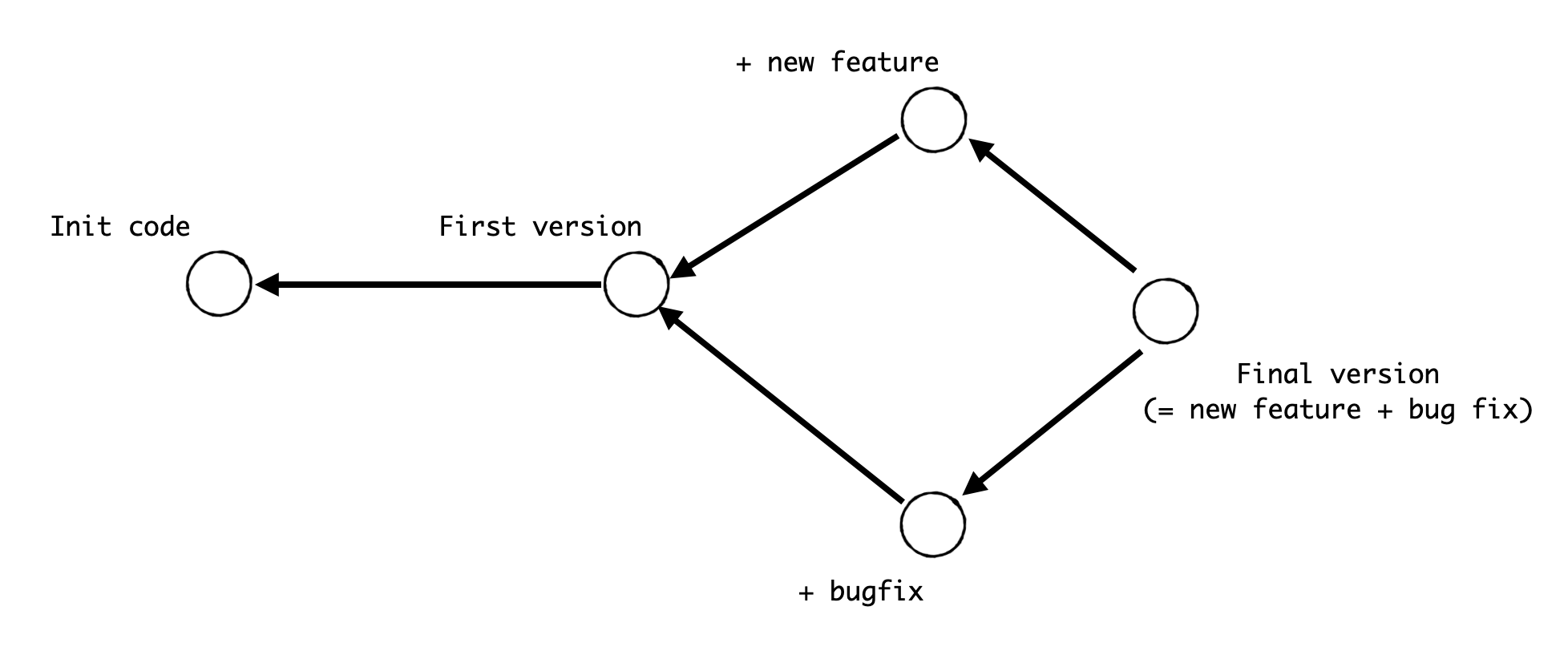
combine multiple snapshots into one is called a merge
Final version consists of First version code, new feature code and bugfix code
Pseudocode
How git represent data type
1 2 3 4 5 6 7 8 9 10
type blob = array<byte> // blob consists of array of bytes type tree = map< string , tree | blob > // tree is a dictionary(map) of <string,tree> or <string,blob> pairs type commit = struct{ parents : array <commit> author : string message : string snapshot : tree }
How git store data
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
type object = tree | blob | commit // tree, blob and commit are treated as object objects = map<string , object >
def store(obj): id = sha1(obj) objects[id] = obj
def load(id): return objects[id] //every objects now have an unique id but it is not human-readable
type referrences = map<string , string> //map human-readable name to hashstring(the id)
Command line interface
Make a directory into a git repository
1 2
$ git init Initialized empty Git repository in ~/GitRepository/.git/
Read the git manual
1 2 3 4 5 6 7 8 9 10 11 12 13
# $ git help TheCmdYouNeedHelp $ git help init GIT-INIT(1) Git Manual GIT-INIT(1)
NAME git-init - Create an empty Git repository or reinitialize an existing one
Untracked files: (use "git add <file>..." to include in what will be committed) bar.txt foo/
nothing added to commit but untracked files present (use "git add" to track)
Add the files you want to take snapshot of
1 2 3 4 5 6 7 8 9 10 11 12 13
$ git add foo $ git status On branch master
No commits yet
Changes to be committed: (use "git rm --cached <file>..." to unstage) new file: foo/bar.txt
Untracked files: (use "git add <file>..." to include in what will be committed) bar.txt
Take the snapshot (will create a node in the graph)
1 2 3 4 5 6 7 8 9
$ git commit # this will prompt a vim window and let you edit the commit message [master (root-commit) 79625e5] Add directory 'foo' but ignore the file out of foo 1 file changed, 1 insertion(+) create mode 100644 foo/bar.txt # Notice that `79625e5` is the hash id of this commit
# git commit only snapshot what have already been added # This give user flexibility to control what should be included in, you might want to exclude things like logs
Show all the history
1
$ git log
Show all the history in a graph view (like the picture above)
Add directory 'foo' but ignore the file out of foo # HEAD and master are referrence # HEAD always points to the current commit # master points to the most up-to-date version (you want to release)
Add directory 'foo' but ignore the file out of foo # go back to master # git checkout 7765ac0c8 $ git checkout master $ tree ../GitRepository ../GitRepository ├── bar.txt └── foo └── bar.txt
# Compare to HEAD as default $ git diff bar.txt diff --git a/bar.txt b/bar.txt index 307edfd..5311602 100644 --- a/bar.txt +++ b/bar.txt @@ -1,2 +1,3 @@ Git is awesome one new line +hhh $ git diff 79625e bar.txt diff --git a/bar.txt b/bar.txt new file mode 100644 index 0000000..5311602 --- /dev/null +++ b/bar.txt @@ -0,0 +1,3 @@ +Git is awesome +one new line +hhh
commit file with part control
1
$ git add -p filename
Branches
Branches are nothing but references, they separate your work flow logically
# first version of loader.py $ cat loader1.py from os import system for i in range(10): system("python3 hello.py")
# second version of loader.py $ cat loader2.py from sys import argv from os import system try: for i in range(int(argv[1])): system("python3 hello.py") except: print("usage : ...")
# see how version 2 differs from version1 # diff old_file new_file # > means only exist in new_file # < means only exist in old_file # a stand for add # c stand for change # number indicate line and column $ diff loader1.py loader2.py 0a1 > from sys import argv 2,3c3,7 < for i in range(10): < system("python3 hello.py") --- > try: > for i in range(int(argv[1])): > system("python3 hello.py") > except: > print("usage : ...")
# The unified way # as used by `git diff` $ diff -u loader1.py loader2.py --- loader1.py 2022-04-15 22:30:19.000000000 +0800 +++ loader2.py 2022-04-30 16:56:39.000000000 +0800 @@ -1,3 +1,7 @@ +from sys import argv from os import system -for i in range(10): - system("python3 hello.py") +try: + for i in range(int(argv[1])): + system("python3 hello.py") +except: + print("usage : ...")
# elide the `--global` for only the local repository $ git config user.name "rainbow" $ cat .git/config [core] repositoryformatversion = 0 filemode = true bare = false logallrefupdates = true ignorecase = true precomposeunicode = true [user] name = rainbow
File status
Modified : changed but not staged yet
Staged : ready to commit, but can be removed
Committed: saved in history
How to write commit message
A brief summary
A detailed explanation
can have several paragraphes
no longer than 72 characters per line(in facilitate with git log)
Separated by a blank line
Advanced git
git commit -a
-a flag will commit all modified(tracked) files, (excluding new files, they are untraced), skipping the staging step
1 2 3 4 5 6 7 8 9 10 11 12
$ git status On branch master Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory) modified: hello.py
Untracked files: (use "git add <file>..." to include in what will be committed) check_all.py
no changes added to commit (use "git add" and/or "git commit -a")
This command serve as shortcut for git add + git commit, making commit small changes a piece of cake.
git log -p
-p flag stand for patch, this cmd use current commit as base, run diff -u
git show
Show diff -u info about given commit ID (what changes are made in the given commit?)
1
$ git show 0b0a183861718ab7ae4107833c71e0f0b5eb97c7
git log –stat
Show a statistic summary of file changes
pipe into editor
1
$ cmd | vim -
git diff
If you forget what you have change before you commit, you can use git diff to show all modifications you have made.
git rm and git mv
Just like rm and mv on Linux, but git automatically staging these changes
Restore modifications of a given file (which is not staged)
use “git restore …” to discard changes in working directory
Also, the -p flag will give an interactive mode(short for part control).
git restore –staged
“git restore –staged …” to unstage
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
$ git add . $ git status On branch master Changes to be committed: (use "git restore --staged <file>..." to unstage) modified: check_all.py new file: output $ git restore --staged output $ git status On branch master Changes to be committed: (use "git restore --staged <file>..." to unstage) modified: check_all.py
Untracked files: (use "git add <file>..." to include in what will be committed) output
git commit –amend
If you amend something that has been written such as a law, or something that is said, you change it in order to improve it or make it more accurate.
You can override previous commit with current commit by using this command
Useful when you want to amend the commit message.
Avoid amend commit to public repository
RollBack
git revert
*Create a new commit which cancelling all modifications in the given commit*
# revert to any given commit # This will create a new commit which cancelling all changes in given commitID based on HEAD # * ---> * ---> * ---> * # C0 --> C1 --> C2 --> HEAD # Now HEAD = C0+C1+C2
# $ git revert C1 # create a new commit # * ---> * ---> * ---> * ---> * # C0 --> C1 --> C2 --> Old_HEAD --> HEAD # Now HEAD == (C0+C1+C2)-C1 == C0+C2 # really ?
If two branch modify the same location, git will not be able to merge automatically. We need to manually edit the file and then commit them
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
$ git merge newfeature Auto-merging check_all.py CONFLICT (content): Merge conflict in check_all.py Automatic merge failed; fix conflicts and then commit the result. $ git status On branch master You have unmerged paths. (fix conflicts and run "git commit") (use "git merge --abort" to abort the merge)
Changes to be committed: new file: functions.py
Unmerged paths: (use "git add <file>..." to mark resolution) both modified: check_all.py
$ git fetch $ git log remotes/origin/master --oneline f250a86 (origin/master) modify README.md 8c4dd6d Update README.md 5160817 (HEAD -> master) Create README.md 78faefa Finish the basic functionality $ git status On branch master Your branch is behind 'origin/master' by 2 commits, and can be fast-forwarded. (use "git pull" to update your local branch)
nothing to commit, working tree clean $ git merge origin/master Updating 5160817..f250a86 Fast-forward README.md | 2 ++ 1 file changed, 2 insertions(+) $ git status On branch master Your branch is up to date with 'origin/master'.
nothing to commit, working tree clean
Work with new branch from remote
1 2 3 4 5 6 7 8 9 10 11 12
$ git fetch ... * [new branch] experiment -> origin/experiment $ git branch -a * master remotes/origin/experiment remotes/origin/master # git will automatically create a local branch via copying from remote $ git checkout experiment Branch 'experiment'set up to track remote branch 'experiment' from 'origin'. Switched to a new branch 'experiment'
Create new branch and send it to remote
Just tell git your upstream via -u
1 2 3
$ git push -u origin NewBranchName # git push --set-upstream origin NewBranchName # Rename : With a -m or -M option, <oldbranch> will be renamed to <newbranch>
Rebase
Make the commit history linear
Rebasing instead of merging rewrites history and maintains linearity, making for cleaner code, it is just an alternative to git merge
1
$ git rebase BranchName
GitHub has some good documentation on how to handle them when they happen: