User only need to specify what data they want rather than the strategy on how to query the data
Three part of SQL
Data Manipulate Language(DML)
Data Definition Language(DDL)
Data Control Language(DCL)
SQL is based on bags(duplicate) rather then sets(no-duplicate)
Basic Syntax
1 2 3 4
SELECT column1,column2,... FROM Relation WHERE predicate1,...; # it's OK to use lowercase key word # However, use capital for key words is convention select column1,column2,... from Relation where predicate1,...;
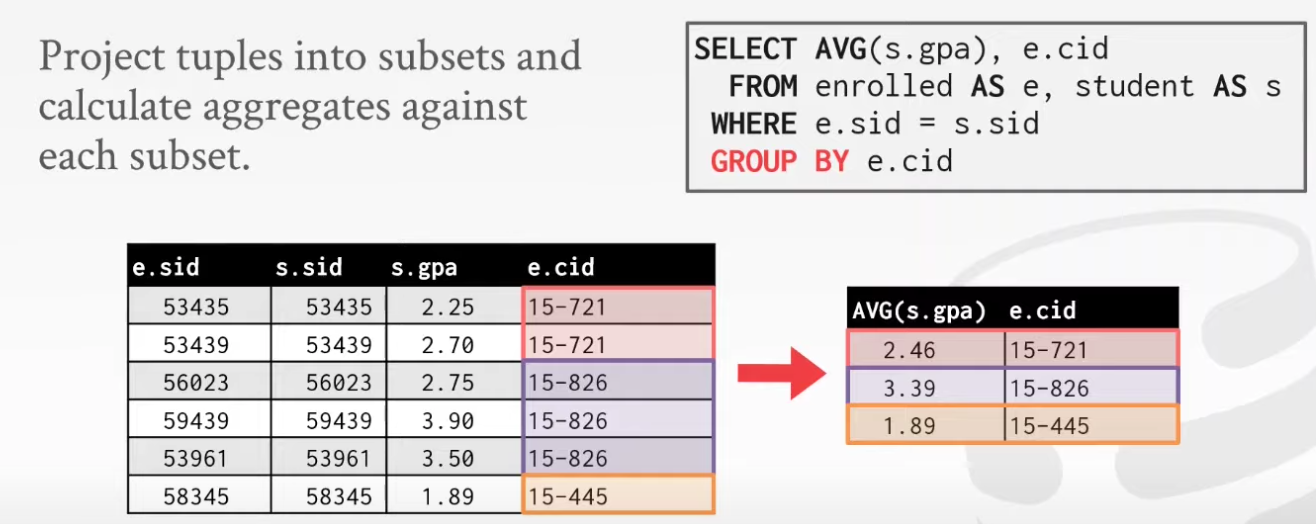
Aggregation+Group by
Aggregate: return a single value from a bag of tuples
Group by : Project tuples into subset and calculate aggregate against each subset
1
GROUPBY
String/Date/Time Operation
In mysql string is case-insensitive while in sql-92 it is case sensitive
Like
1 2 3 4
# matchany substring : % # match exactly onecharacter : _ SELECT*FROM student AS s WHERE s.login LIKE'%@cs'; SELECT*FROM enrolled AS e WHERE e.cid LIKE'15-7_1';
String functions
Each DBMS have its own implementation
String concatenation
1 2
'a'||'b' # insql-92 CONCAT('a','b') # in MySQL
Date Operation
differs widely between different DBMS
Output Control + Redirection
Redirect the query result to another new table
INTO
1
SELECTDISTINCT cid INTO newtable FROM enrolled;
INSERT
1 2
INSERTINTO existTable (SELECTDISTINCT cid FROM enrolled); # query result must generate the same columns as the to be inserted table
Order by
1 2 3
# order the results by a specified order SELECT sid,grade FROM enrolled WHERE cid='15-721'ORDERBY grade ; SELECT sid,grade FROM enrolled WHERE cid='15-721'ORDERBY grade [DESC|ASC];
Limit
limit the number returned by querying
1 2
SELECT*FROM student LIMIT 5; # get the first5 students SELECT*FROM student LIMIT 5OFFSET2; # get student 2~7
Nested Queries
IN/ANY/ALL/EXISTS
1 2 3
SELECT name FROM student WHERE sid IN(SELECT sid FROM enrolled); SELECT name FROM student WHERE sid ALL(SELECT sid FROM enrolled); # IN (first query)
Common Table Expression
create temporary table in large query
1
WITH sname AS (SELECT1) SELECT*FROM sname;
recursion can be implemented via common table expression
Window Function
performs a “sliding” calculation across a set of tuples are related.
import sqlite3 as sql open('new.db','wb').close() con = sql.connect('new.db') cur = con.cursor() cur.execute("CREATE TABLE shows (id INTEGER , title TEXT , PRIMARY KEY(id))") cur.execute("CREATE TABLE genres (show_id INTEGER , genre TEXT , FOREIGN KEY(show_id) REFERENCES shows(id))")
import csv
withopen('favorites.csv','rt') as file: reader = csv.DictReader(file) cot = 1 for row in reader: title = row['title'].strip().lower() cmd = 'INSERT INTO shows (id , title) VALUES({} , "{}")'.format(cot , title) cur.execute(cmd) for genre in row['genres'].split(): cmd = 'INSERT INTO genres (show_id , genre) VALUES( {} , "{}")'.format(cot , genre) cur.execute(cmd) cot += 1 con.commit() # Don't forget to commit ! con.close() print("OK")
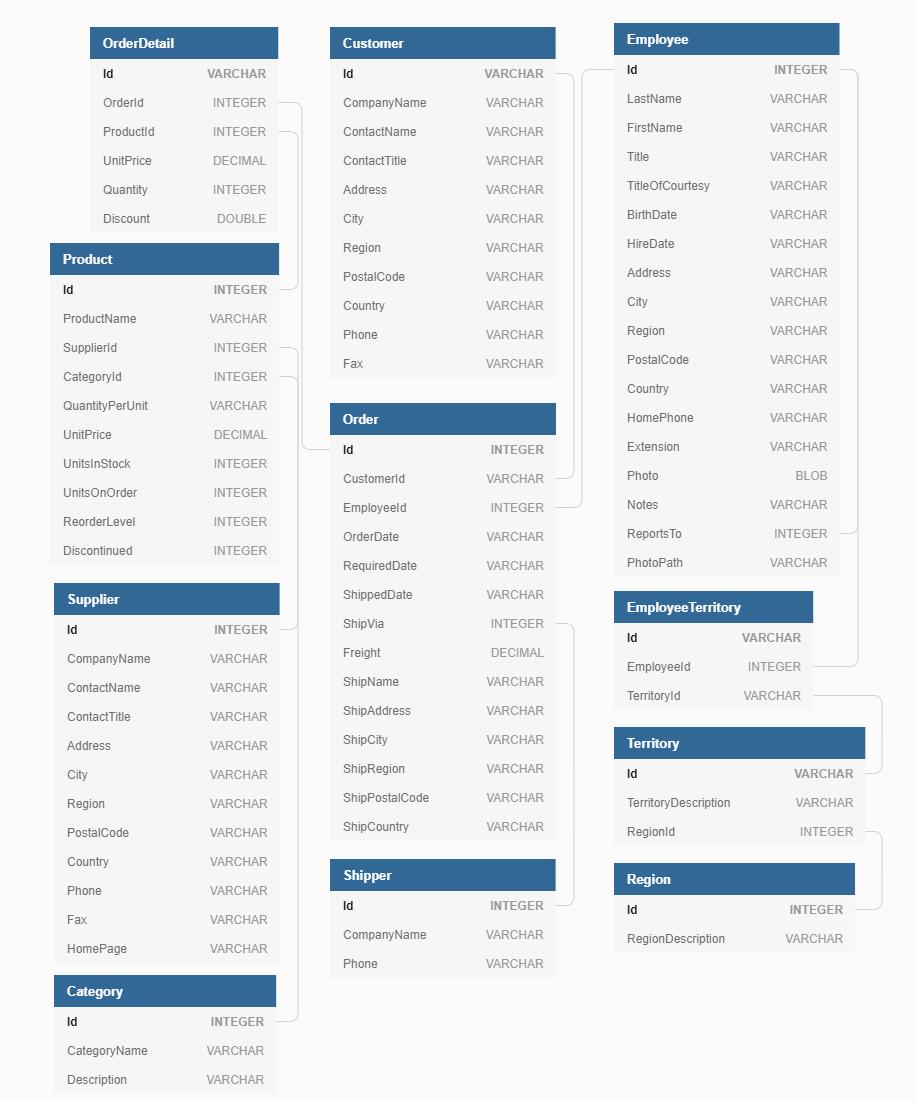
The homework contains 10 questions in total and is graded out of 100 points. For each question, you will need to construct a SQL query that fetches the desired data from the SQLite DBMS. It will likely take you approximately 6-8 hours to complete the questions.
SELECT CategoryName FROM Category ORDERBY CategoryName;
Q2
Get all unique ShipNames from the Order table that contain a hyphen '-'.
Details: In addition, get all the characters preceding the (first) hyphen. Return ship names alphabetically. Your first row should look like Bottom-Dollar Markets|Bottom
INSTR() -- Find a substring in a string and returns an integer indicating the position of the first occurrence of the substring. SUBSTR() -- Extract and returns a substring with a predefined length starting at a specified position in a source string
Q3
Details: You should print the Order Id, ShipCountry, and another column that is either 'NorthAmerica' or 'OtherPlace' depending on the Ship Country. Order by the primary key (Id) ascending and return 20 rows starting from Order Id 15445 Your output should look like 15445|France|OtherPlace or 15454|Canada|NorthAmerica
1 2 3 4 5 6 7
SELECT Id,ShipCountry, CASE WHEN ShipCountry IN ('USA', 'Mexico','Canada') THEN 'NorthAmerica' ELSE 'OtherPalce' END FROM 'Order' WHERE Id >= 15445 ORDER BY ID ASC LIMIT 20 ;
Q4
For each Shipper, find the percentage of orders which are late.
Details: An order is considered late if ShippedDate > RequiredDate. Print the following format, order by descending precentage, rounded to the nearest hundredths, like United Package|23.44
-- First get order count SELECT ShipVia, COUNT(ShipVia) FROM Shipper AS S INNERJOIN'Order'AS O ON S.Id=O.ShipVia GROUPBY O.ShipVia;
-- Then get later count SELECT ShipVia,COUNT(ShipVia) FROM Shipper AS S INNERJOIN'Order'AS O ON S.Id=O.ShipVia WHERE O.ShippedDate > O.RequiredDate GROUPBY O.ShipVia;
-- Finally calculate the percentage
SELECT ROUND(late*100.0/cnt,2) ASpercentFROM
(SELECT ShipVia, COUNT(ShipVia) AS cnt FROM Shipper AS S INNERJOIN'Order'AS O ON S.Id=O.ShipVia GROUPBY O.ShipVia) AS cntT
INNERJOIN
(SELECT ShipVia,COUNT(ShipVia) AS late FROM Shipper AS S INNERJOIN'Order'AS O ON S.Id=O.ShipVia WHERE O.ShippedDate > O.RequiredDate GROUPBY O.ShipVia) AS lateT
(SELECT ShipVia, COUNT(ShipVia) AS cnt FROM Shipper AS S INNERJOIN'Order'AS O ON S.Id=O.ShipVia GROUPBY O.ShipVia) AS cntT
INNERJOIN
(SELECT ShipVia,COUNT(ShipVia) AS late FROM Shipper AS S INNERJOIN'Order'AS O ON S.Id=O.ShipVia WHERE O.ShippedDate > O.RequiredDate GROUPBY O.ShipVia) AS lateT
ON cntT.ShipVia=lateT.ShipVia
INNERJOIN'Shipper'AS S ON S.Id=cntT.ShipVia ORDERBYpercentDESC;
Q5
Details: Get the number of products, average unit price (rounded to 2 decimal places), minimum unit price, maximum unit price, and total units on order for categories containing greater than 10 products. Order by Category Id. Your output should look like Beverages|12|37.98|4.5|263.5|60
You often use the HAVING clause with the GROUP BY clause. The GROUP BY clause groups a set of rows into a set of summary rows or groups. Then the HAVING clause filters groups based on a specified condition.
1 2 3 4 5 6 7 8 9 10 11
SELECT column_1, column_2, aggregate_function (column_3) FROM table GROUPBY column_1, column_2 HAVING search_condition;
1 2 3 4 5
-- First, get categoryId whose size >= 10 SELECT CategoryId , COUNT(*) AS C FROM Product GROUPBY CategoryId HAVING C>=10;
-- Then, join it with Category Table SELECT CategoryName , C FROM (SELECT CategoryId , COUNT(*) AS C FROM Product GROUPBY CategoryId HAVING C>=10) AS P INNERJOIN Category ON P.CategoryId=Category.Id;