Storage
Storage hierarchy
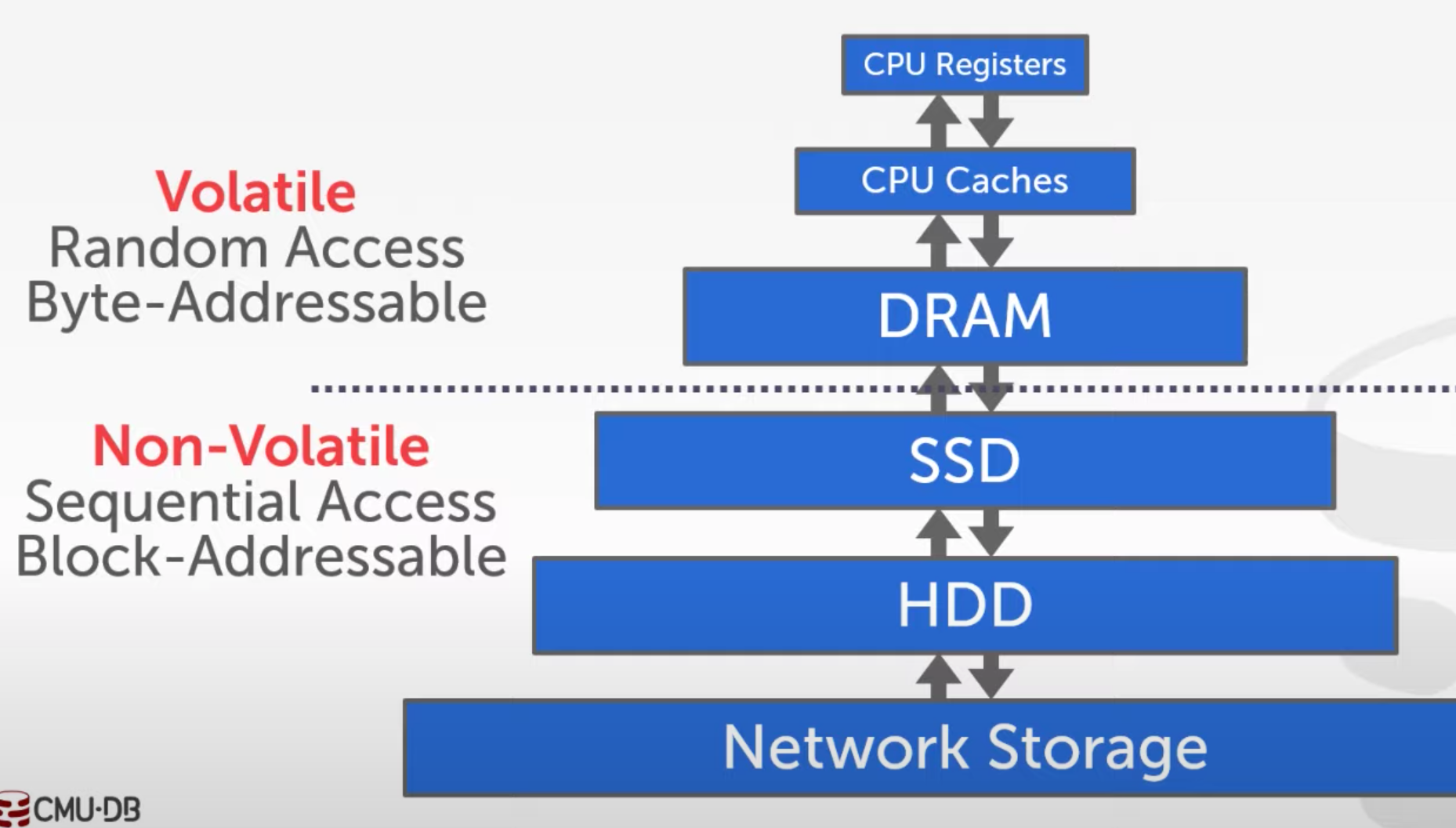
Note that when accessing the slow, non-volatile device, we are recommended to read a whole block at a time
Goal
Just like the virtual memory system provided by OS, DBMS should provide other applications with the illusion that the whole database is stored in memory despite the fact that it is stored on disk.
Implementation
DBMS should try their best to reduce the cost of moving data
- read/write disk as few as you can
- avoid large stall
This seems like the job OS should do
Why not use OS ?
1 | mmap(); |
The OS cannot understand your storage operation patterns, raising performance bottleneck later. The replace algorithm should be different !
- Flushing dirty page to disk in correct order
- Sepecification prefetching
- Buffer replace algorithm
- Thread/process scheduling
- Cocurrency problem
DBMS always want to control every thing rather than delegating the job to OS
How DBMS represent data on disk?
File storage
Database is just file. One file or more. For the OS, it is not special
1 | $ file new.db |
- The format is specified to DBMS, you cannot open a
SQLitedatabase withMySQL - Some database may be multi-file to avoid file system storage limitation
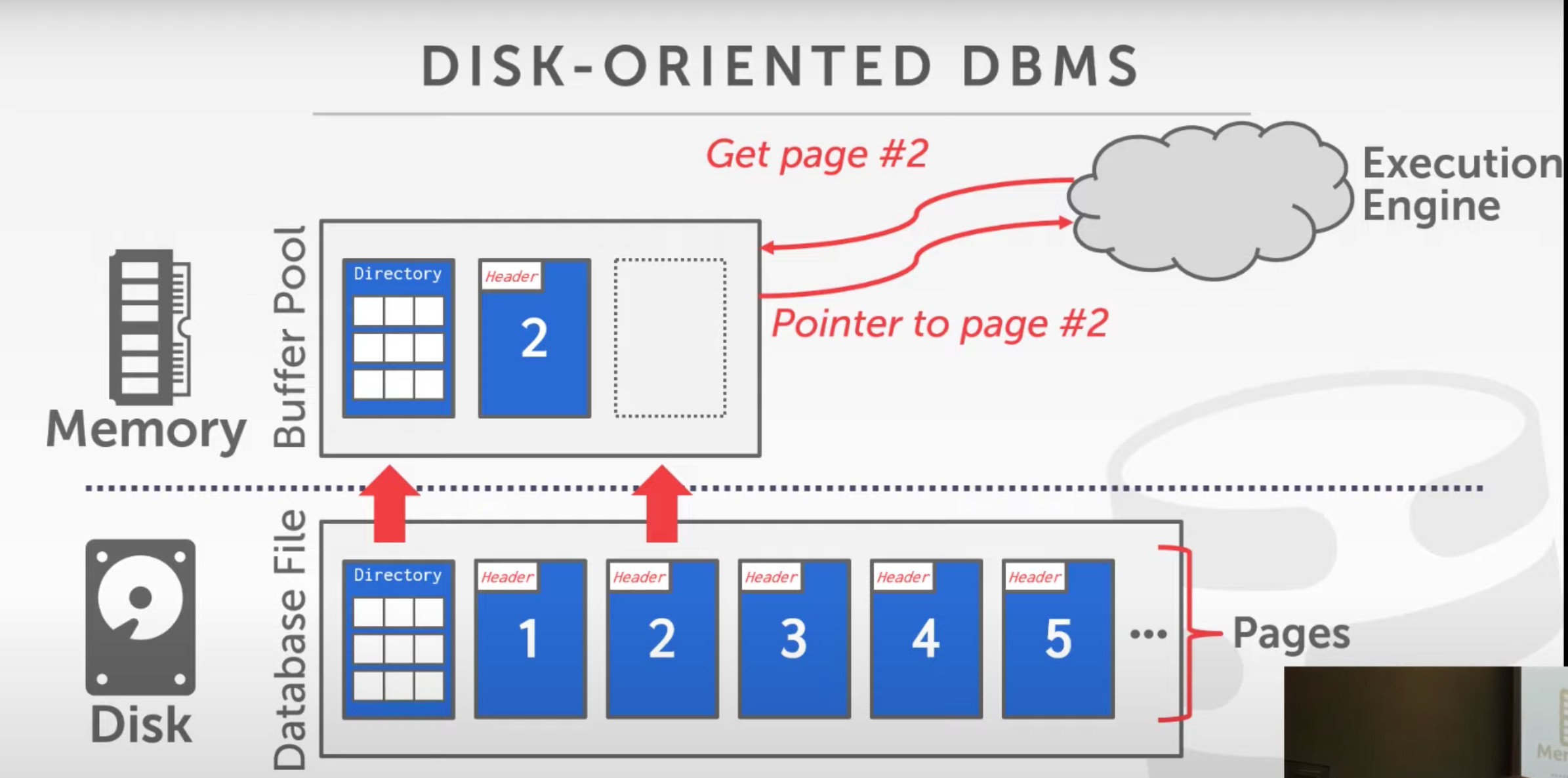
Storage manager
Responsible for managing the database file
- Some may have customized read/write scheduling
- Organize files as collection of
pages(Don’t muddle up with pages in VM, it is just a block of bytes)

- Each page has a unique page ID generated by the DBMS, later mapped to physical location
Page hierarchy
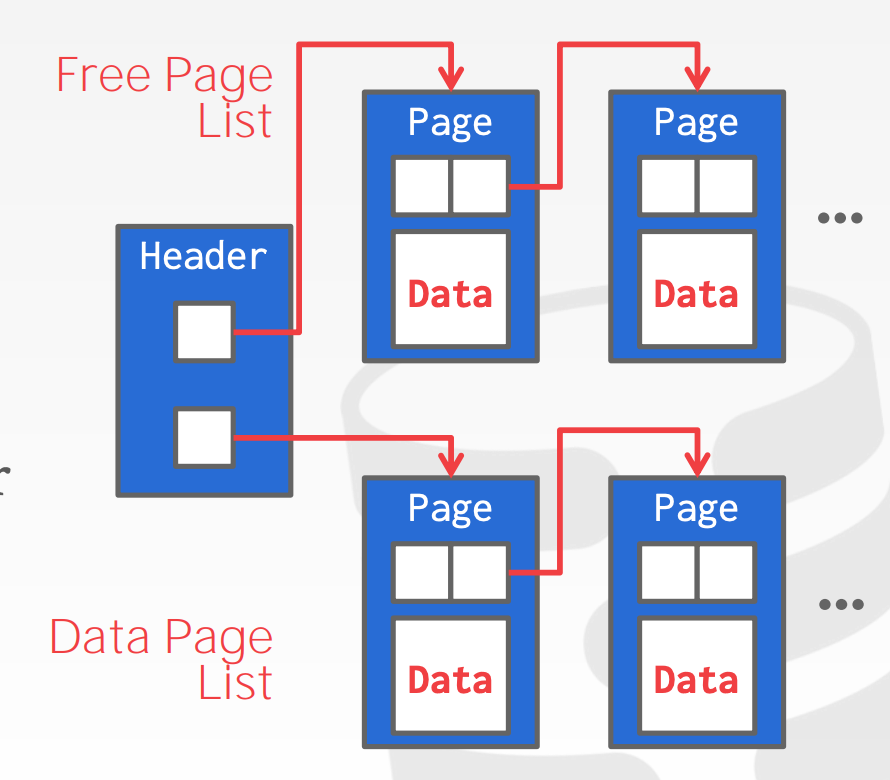
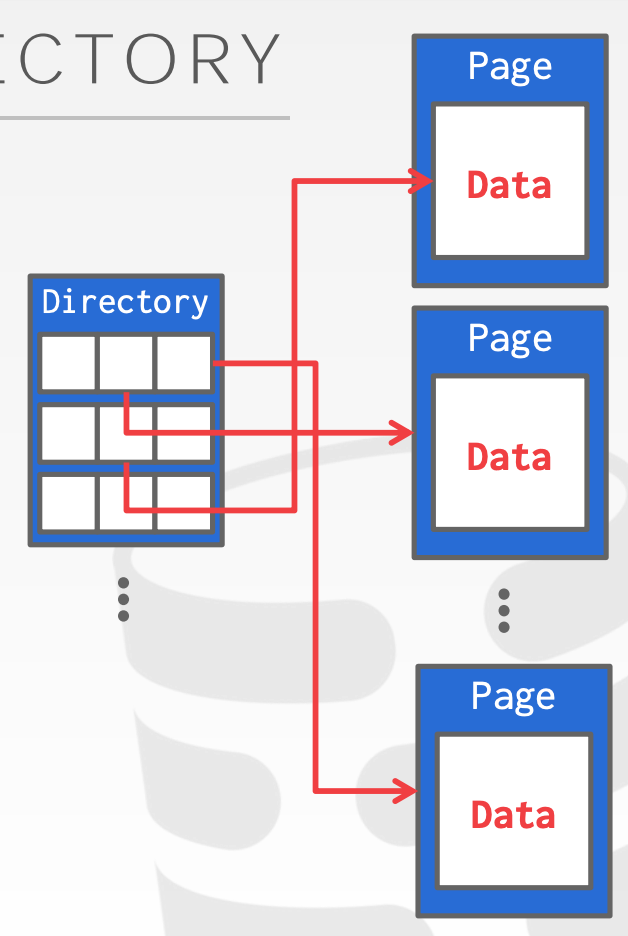
Heap file organization
- must support traversal of all pages
- Implemented in page directory(sync the directory page with data pages) or linked list(maintain a header page)
Sequencial file organization
Hashing file organization
….
Page layout
How data is organized inside a page
Page header
Every page contains a header of metadata about the page’s contents.
- Page Size
- Checksum
- DBMS Version
- Transaction Visibility
- Compression Information
- …
Tuple-oriented
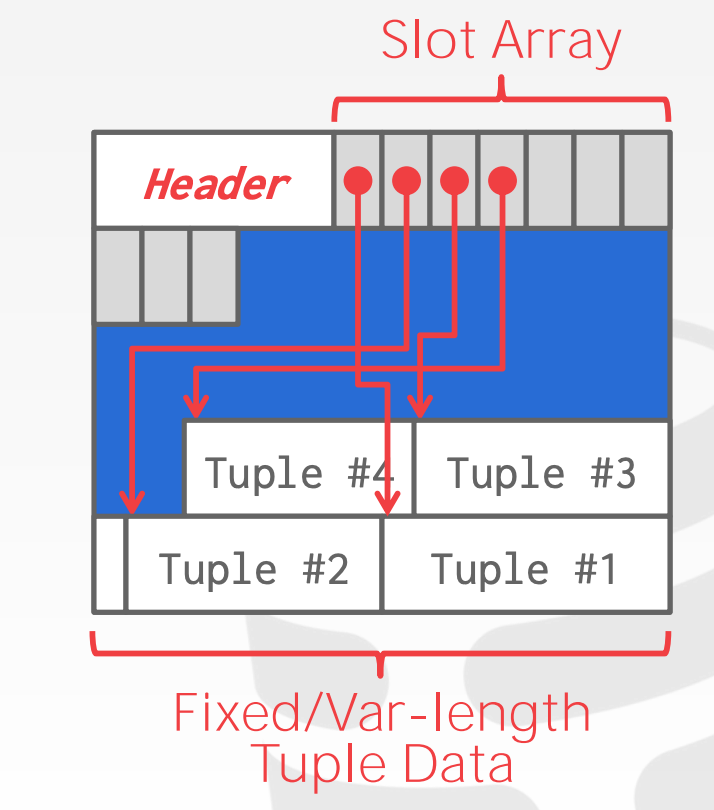
- There can be tuples with different length
- Easy rearrangement
- Only middle of the page is wasted(the gap)
Log-structured
The system appends log records to the file of how the database was modified
(Sequential write operation, fast)

To read a record, the DBMS scans the log backwards and “recreates” the tuple to find what it needs.

Tuple layout
A tuple is just a sequence of bytes
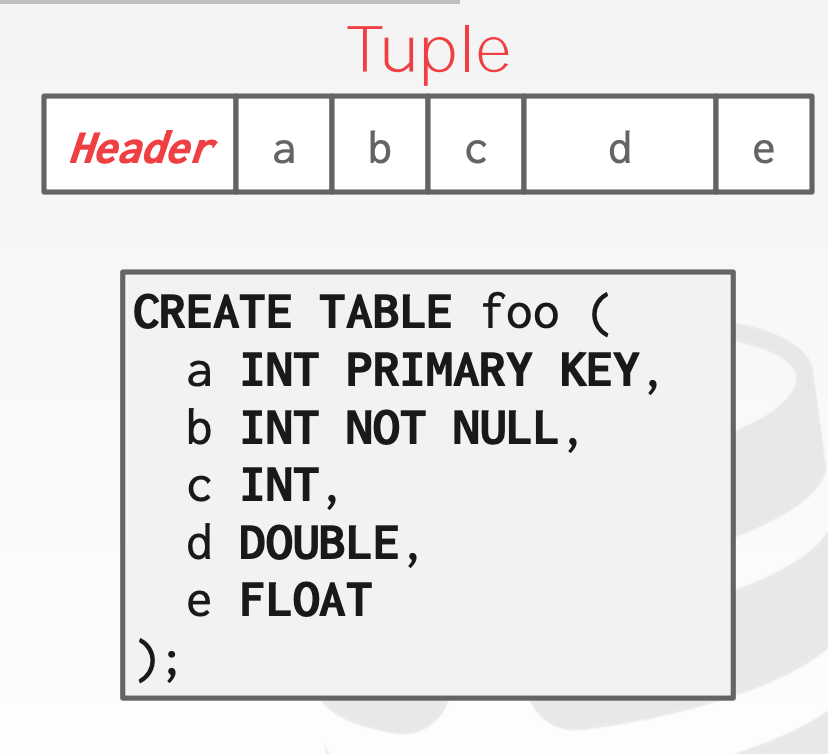
- Header store some meta data like visibility info (concurrency control)or Bit Map for NULL values.
- We do not need to store meta-data about the schema.
- Attributes are typically stored in the order that you specify them when you create the table
Data Representation
Some DBMS build their own type for numbers in order to have more control
1
2
3
4
5
6
7
8typedef struct integer{
...
} LargeInteger ;
typedef struct floating{
...
} Float ;
LargeInteger add(LargeInteger a , LargeInteger b);
...- large range
- more precision
- …
What if a tuple is too large for one page?
- An auxiliary
overflow pageis used, then we only store a pointer to the overflow page at original position
- An auxiliary
How about large binary files, for example the Netflix Movie DB
- use
BLOBdata type provided by some database - Again we only store pointers to files, let the data be in where they are on the disk(Bad idea, we lose our control and protection!)
- use
System catalog
DBMS store attribute infomation of tuples
INFORMATOIN_SCHEME
Workload
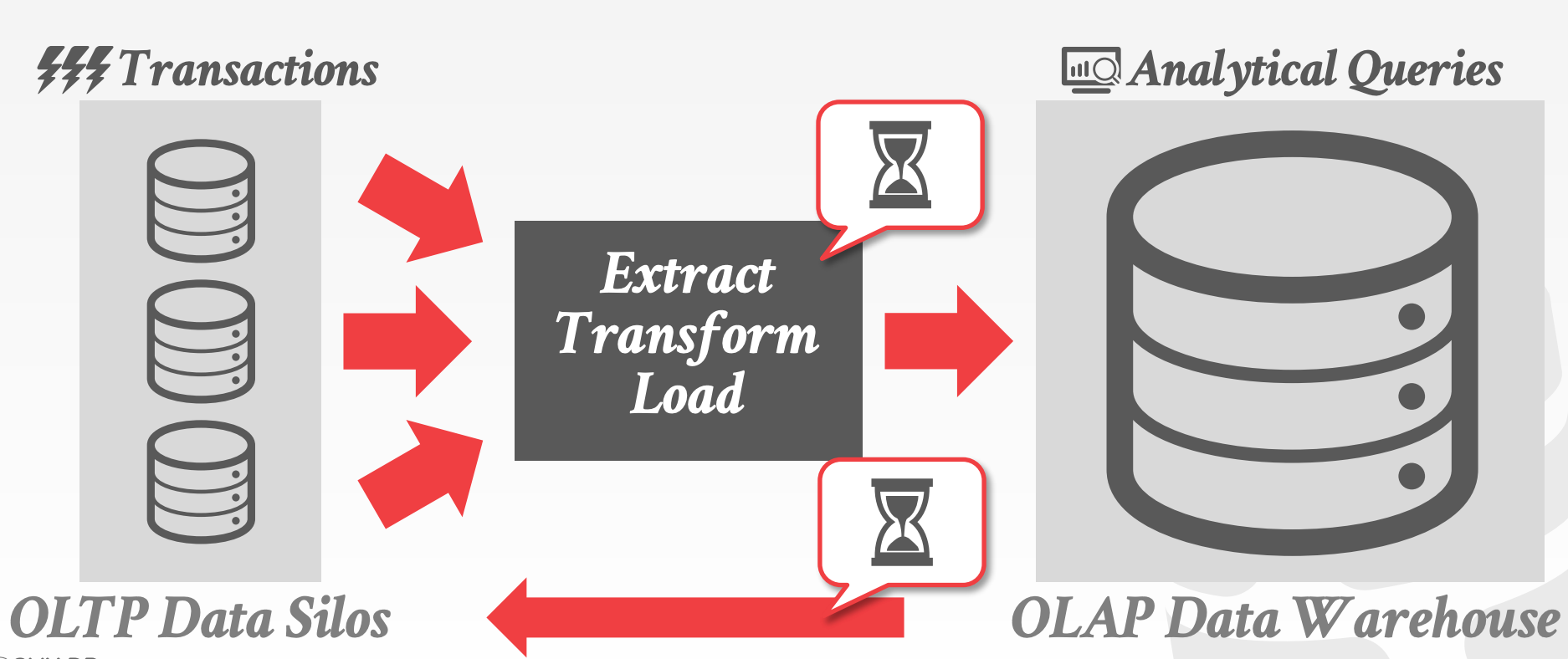
DBMS mainly has two kinds of operation OLTP and OLAP
- OLTP(On-Line Transaction Process) : read/write small amount of data frequently
- The storage model should be row-based
- The DBMS stores all attributes for a single tuple contiguously in a page
- OLAP(On-Line Analytic Process) : read large amount data to perform statistic analysis
- The storage model should be column-based
- The DBMS stores the values of a single attribute for all tuples contiguously in a page.