I always appreaciate these guys for letting people watch movie freely, making money from advertising, very old-school way.
Due to my poor Internet connection, I want to donwload the film and watch it without interruption. However, the website do not provide a direct donwload button.
View the source
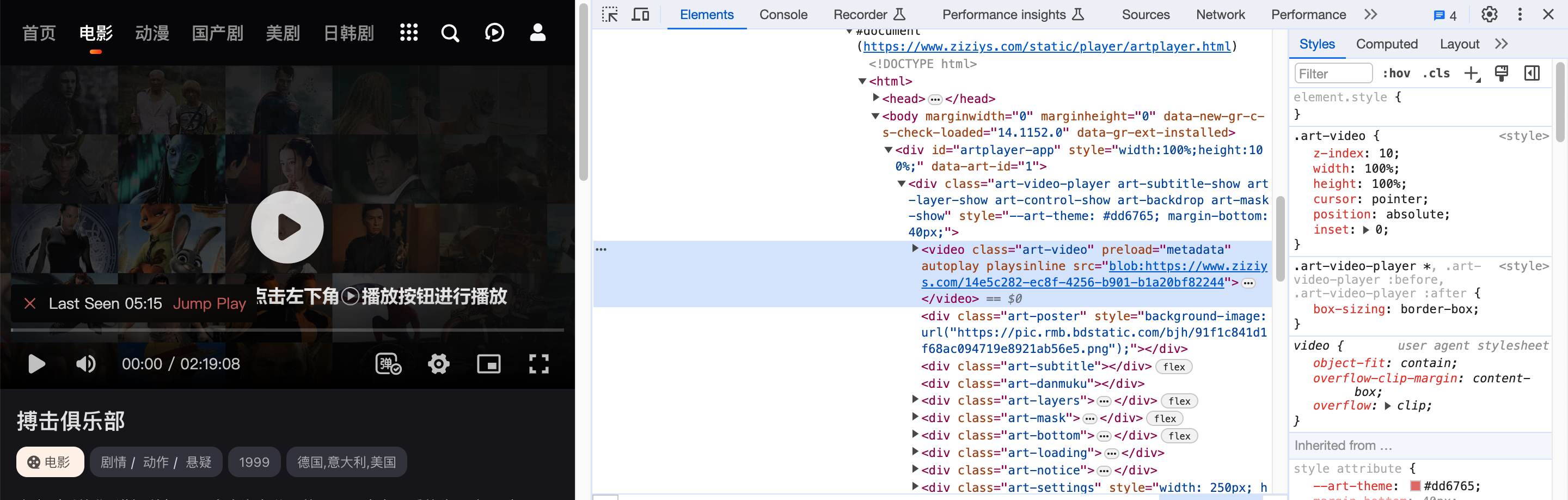
So we just view the page source to see if we can find the video directly from <video src="xxx">
It’s not there, I don’t know what a blob: is.
Network traffic
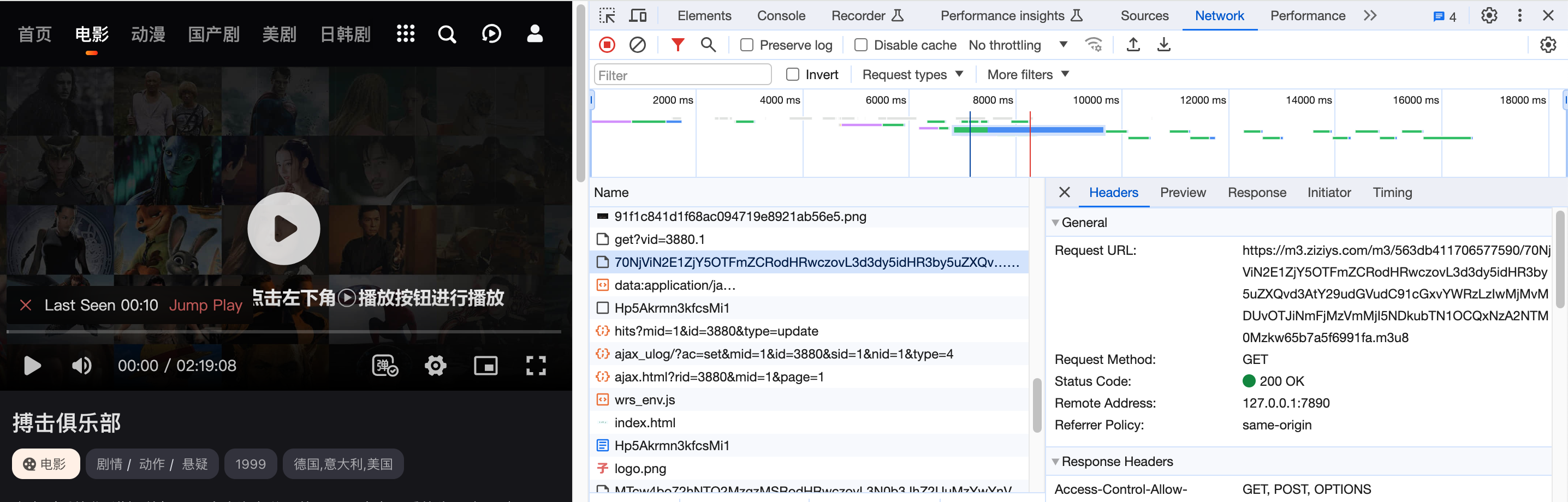
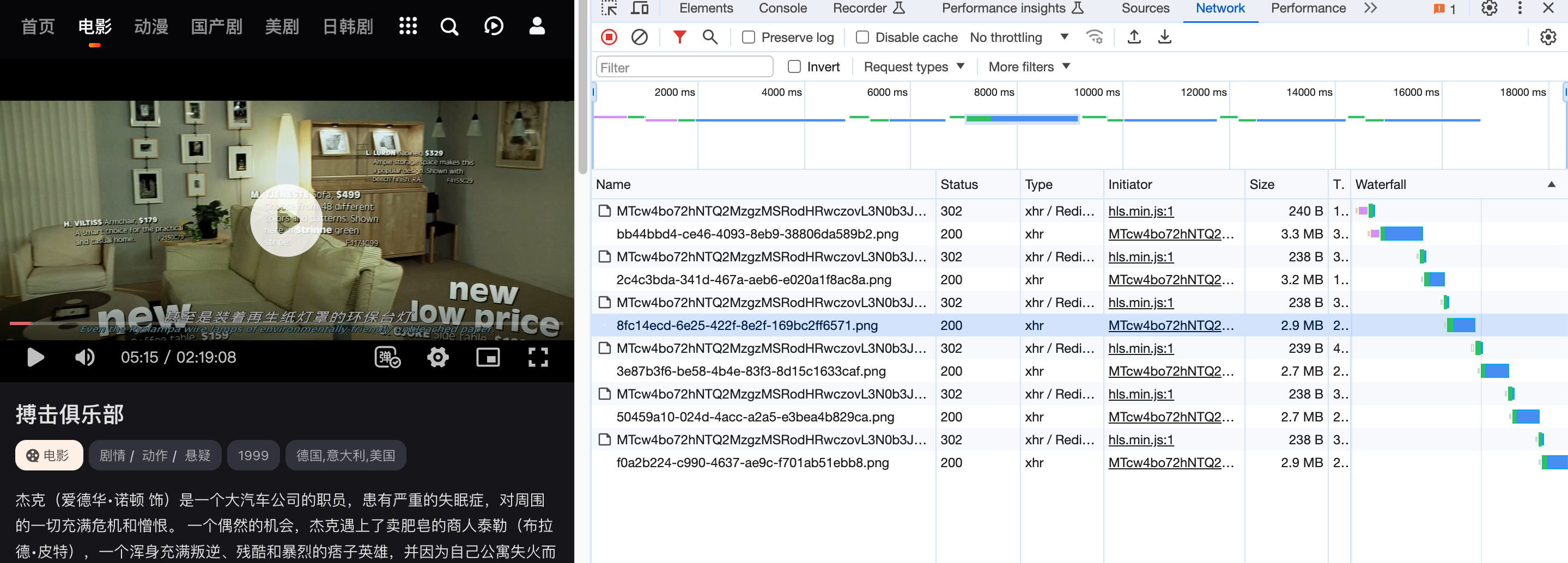
Then I check the network log, the site must send the video through.
Fortunately, I have heard about the m3u8 file, functioning as a donwload list for stream video by small segments.
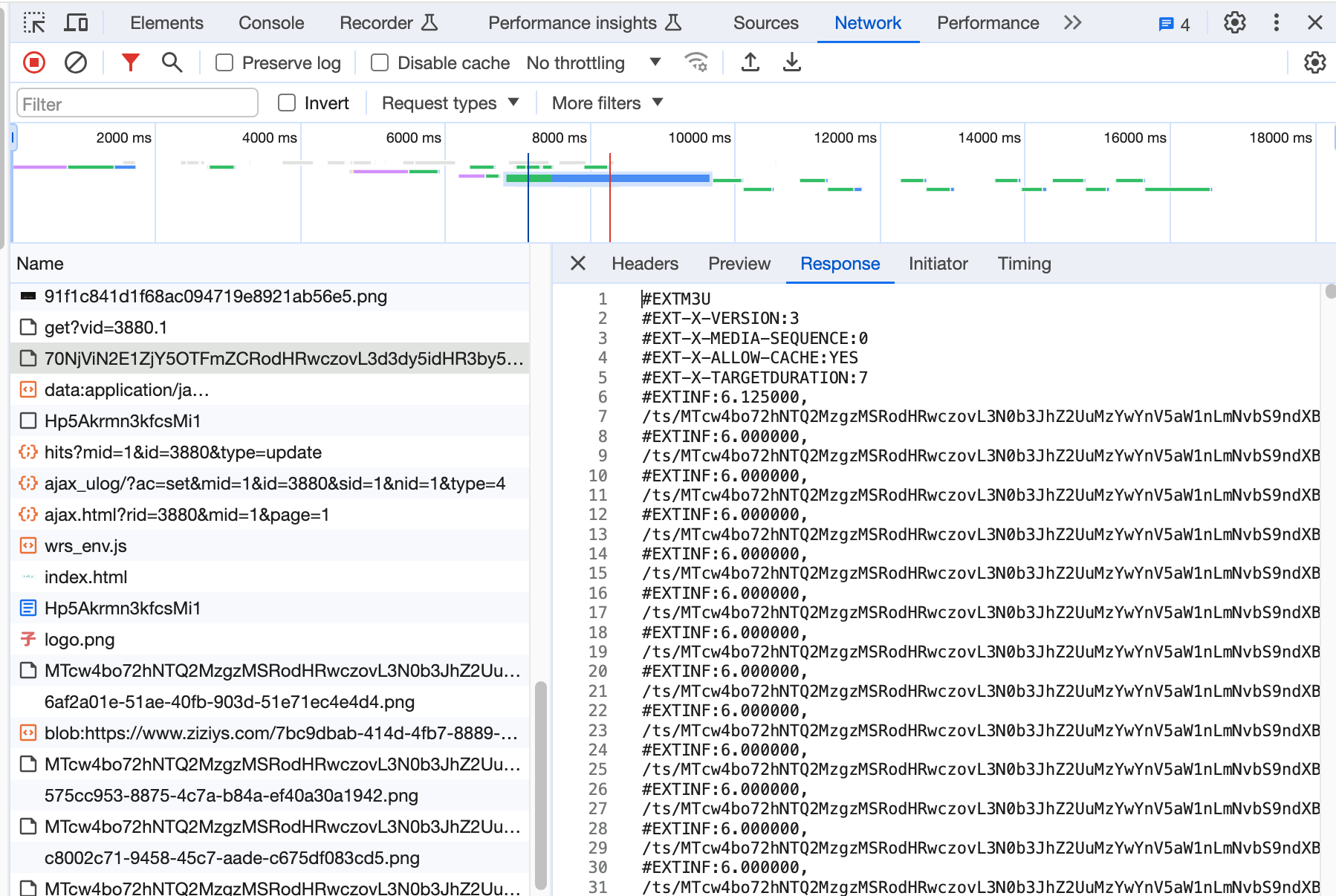
But the m3u8 file does not seems to be a standard one, it doesn’t have the .ts file and unable to directly access.
That confuse me, I then bark at the wrong tree for some time.
View the segments
Just before giving up, an idea hit me, why not just see the streaming process of the segments ?
You can see that the request is not 404, it is actually redirect to a png file.
So it is really import to use a burp suite !!! Don’t be lazy
I don’t know much about the video encoding, but I know that FFmpeg is really powerful. So I just google some thing then find something about ‘video disguise as png’.
import requests as r from tqdm import tqdm url = "https://m3.ziziys.com"
f = open("18NjViNzhmZTg4ZDk5NSRodHRwczovL3d3dy5idHR3by5uZXQvd3AtY29udGVudC91cGxvYWRzLzIwMjMvMDUvOTJiNmFjMzVmMjI5NDkubTN1OCQxNzA2NTI4NzQ065b78fe88d992.m3u8" , "rt")
ua = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.6 Mobile/15E148 Safari/604."
head = { "User-Agent" : ua }
ls = [l for l in f.readlines() if'ts'in l] for index,line in tqdm(enumerate(ls), desc="Downloading items" , total = len(ls)): location = url + line.strip() try: resp = r.get(location , headers = head) except: try: resp = r.get(location , headers = head) except: print("error downloading {}.ts, URL:{}".format(index , location)) continue if resp.status_code == 200: # Actually I expect a 302 here, but it just return the png file without redirection ... withopen("clips/{}.ts".format(index) , "wb") as savefile: savefile.write( resp.content[1:] ) else: print("error downloading {}.ts, URL:{}".format(index , location))
# It costs me fucking 5 hours ! I should have made the script multi-threading. $ py down.py Downloading items: 100%|█████████████████████████████████| 1392/1392 [4:56:34<00:00, 12.78s/it]
# Although there are some warning/error, I successfully get it ! $ ffmpeg -f concat -safe 0 -i filelist.txt -c copy Fight_Club.mp4 ... [h264 @ 0x7fd8ff806340] non-existing SPS 0 referenced in buffering period Last message repeated 1 times [out#0/mp4 @ 0x7fd8fd010100] video:2650522kB audio:197995kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.144595% size= 2852636kB time=02:21:40.98 bitrate=2749.0kbits/s speed=53.2x
Conclusion
Know the detail, but don’t be confused by the detail.
The attack idea is important.
The idea is always the most important.
Revisit
Now we are in 2025, we have AI
The website now use public CDN to host their video clips, fantastic and profitble
import requests from urllib.parse import urlparse from concurrent.futures import ThreadPoolExecutor, as_completed from tqdm import tqdm
urls = [] withopen("../list.m3u8","rt") as f: for line in f: if'.png'in line: urls.append(line.strip())
# Function to download a single URL defdownload_url(url): try: response = requests.get(url) # Simulate a small delay for demonstration purposes (can be removed) withopen("{}".format(urlparse(url).path.split('/')[-1]) ,"wb") as f: f.write(response.content[1:]) return url, len(response.content) # return URL and size of content except requests.RequestException as e: return url, str(e) # If there's an error, return the error message
# Create a ThreadPoolExecutor with a maximum of 30 threads defdownload_urls(urls): results = [] # Initialize ThreadPoolExecutor and progress bar with ThreadPoolExecutor(max_workers=30) as executor: # Track the progress using tqdm with tqdm(total=len(urls), desc="Downloading", unit="url") as pbar: # Submit the download tasks to the thread pool futures = {executor.submit(download_url, url): url for url in urls} # Process each future as it completes for future in as_completed(futures): url, result = future.result() results.append((url, result)) pbar.update(1) # Update the progress bar after each download
return results
if __name__ == '__main__': # Call the download function results = download_urls(urls) # Print the results of each download for url, result in results: print(f"Downloaded from {url}: {result}")
The download get speed up by 30x.
or just use already existing tools : yt-dlp --concurrent-fragments 32 "https://v.lzcdn31.com/20251230/1017_0ff0ee0a/index.m3u8"
(If the .m3u8 file contain .ts files point to a normal video clip instead of a .png, than IINA meidan player can play it directly)
Further investigation
How to use public CDN like xhscdn.com to store your own file ?
The website use Thinkphp V5.0.24, and do a simple search on the Internet, you will find that this version has some unserialize vulnerability to all RCE.